Research Impact of data augmentation in broadband spectrograms
Abstract
Two residual networks are implemented to perform regression for source localization and environment classification using a moving mid-frequency source recorded during the Seabed Characterization Experiment in 2017. The first model implements only classification for inferring the seabed type, and the second model uses regression to estimate the source localization parameters. The training is done using synthetic data generated by the ORCA normal mode model. The architectures are tested on both measured field and simulated data with variations in the sound speed profile and seabed mismatch. Additionally, nine data augmentation techniques are implemented to study their effect on the network predictions. The metrics used to quantify network performance are the root mean square error for regression, and accuracy for seabed classification. The models report consistent results for the source localization estimation and accuracy above 65\% in the worst-case scenario for seabed classification. From the data augmentation study, results show that the more complex transformations such as time warping, time masking, frequency masking, and a combination of these techniques, yield significant improvement of the results using both simulated and measured data.
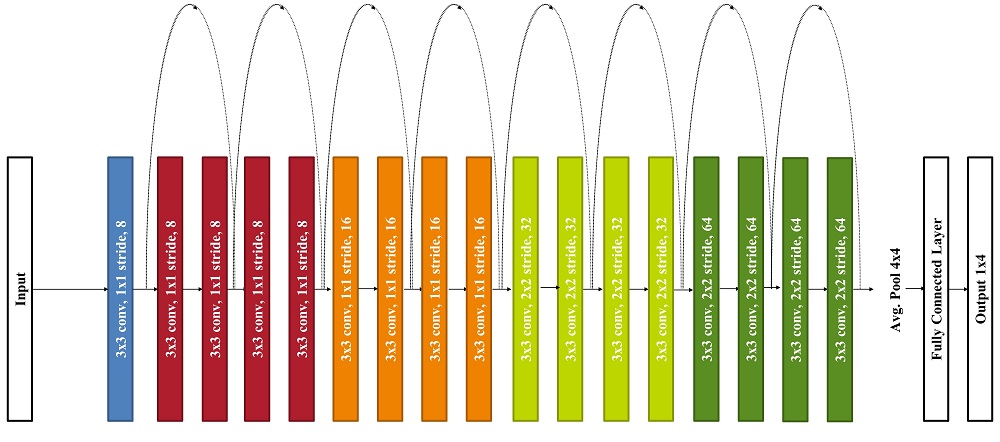
ResNet-18 for source localization and seabed classification tasks. The input of the ResNet-18 architecture consists of a spectrogram of size $1\times80\times1107$, after downsampling and smoothing the raw spectrograms. The output of the network corresponds to the seabed types (for only classification) and the source localization parameters (for only regression). The target variables are the source depth $z_s$, the CPA range $r_{\textrm{CPA}}$, the ship speed $v_\textrm{{ship}}$, and the seabed type or sediment.
Results of networks trained with and without data augmentation applied to synthetic tests A-E. RMSE is calculated for each test set and the five instances of the 3-reg model for source depth, CPA range, and ship speed. Seabed accuracy from the 4-class architecture. The confidence intervals shown at the top of each bar represent the standard deviation $(\sigma)$ of the errors and accuracy, respectively.
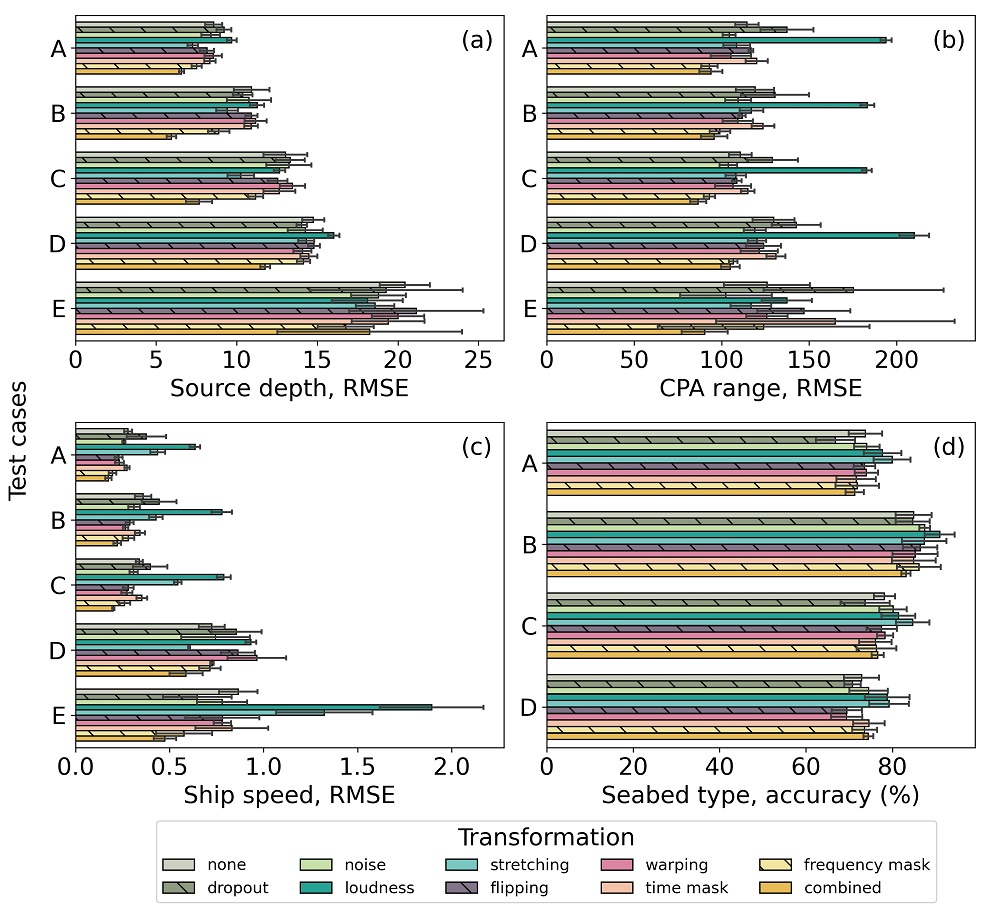
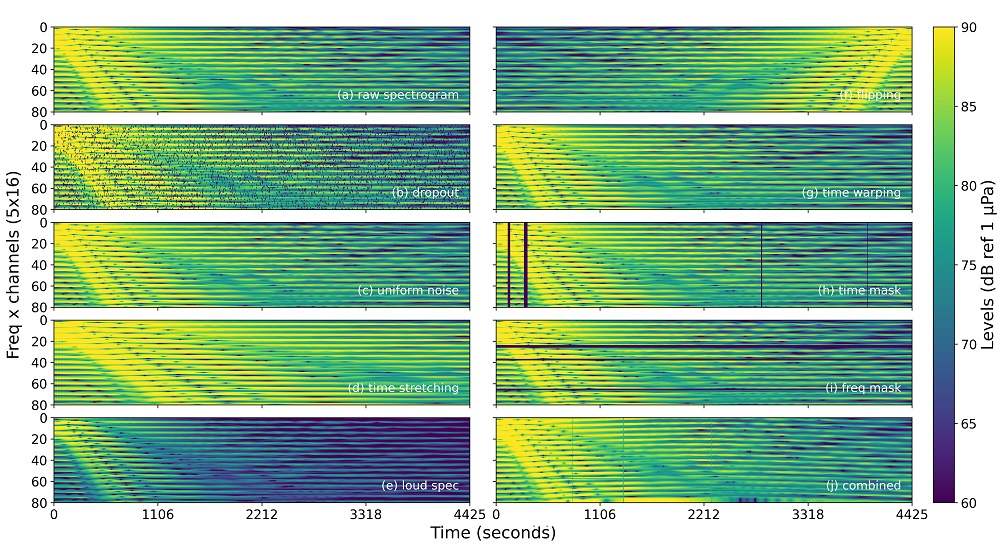
Multiple data transformations have been applied to different testing sets to study the influence of such changes on the accuracy of the models. Out of the nine augmentations implemented during training, the loudness transformation impacted results negatively. Dropout, uniform noise, and time warping augmentations did not contribute to significant improvements for the network predictions. In contrast, time stretching, flipping, time masking, frequency masking, and the combined transformation positively impacted the ability of the trained networks to generalize to synthetic datasets with environmental mismatch and to the measured data samples. The improvement in the predictions showed data augmentation helps deep networks to focus only on the most relevant features in the data during training. Results demonstrated these data transformations are a reliable regularization technique to improve ResNet performance for seabed classification and source localization using mid-frequency spectrograms, outperforming predictions obtained without data augmentation.
Related publications
-
Impact of data augmentation on supervised learning for a moving mid-frequency source
Jhon A. Castro-Correa, Mohsen Badiey, Tracianne B. Neilsen, David P. Knobles, and William S. Hodgkiss. DOI: 10.1121/10.0007284. [PDF]
Related conferences
-
Incidence of data augmentation in machine learning using broadband spectrograms
Jhon A. Castro-Correa, Mohsen Badiey, Tracianne B. Neilsen, David P. Knobles, and William S. Hodgkiss. DOI: 10.1121/10.0004690