5. How does it work?
5.1. Basic Concepts
- 1. Time References
- 5.1.1.1. What is a reference clock?
- 5.1.1.2. How will NTP use a reference clock?
- 5.1.1.3. How will NTP know about Time Sources?
- 5.1.1.4. What happens if the Reference Time changes?
- 5.1.1.5. What is a stratum 1 Server?
- 2. Time Exchange
- 5.1.2.1. How is Time synchronized?
- 5.1.2.2. Which Network Protocols are used by NTP?
- 5.1.2.3. How is Time encoded in NTP?
- 5.1.2.4. When are the Servers polled?
- 3. Performance
- 4. Robustness
- 5.1.4.1. What is the stratum?
- 5.1.4.2. How are Synchronization Loops avoided?
- 5. Tuning
- 6. Operating System Clock Interface
- 5.1.6.1. How will NTP discipline my Clock?
1. Time References
A reference clock is some device or machinery that spits out the current time. The special thing about these things is accuracy: Reference clocks must be accurately following some time standard.
Typical candidates for reference clocks are (very expensive) cesium clocks. Cheaper (and thus more popular) ones are receivers for some time signals broadcasted by national standard agencies. A typical example would be a GPS (Global Positioning System) receiver that gets the time from satellites. These satellites in turn have a cesium clock that is periodically corrected to provide maximum accuracy.
Less expensive (and accurate) reference clocks use one of the terrestrial broadcasts known as DCF77, MSF, and WWV.
In NTP these time references are also named stratum 0, the highest possible quality. (Each system that has its time synchronized to some reference clock can also be a time reference for other systems, but the stratum will increase for each synchronization.)
A reference clock will provide the current time, that's for sure. NTP will compute some additional statistical values that describe the quality of time it sees. Among these values are: offset (or phase), jitter (or dispersion), frequency error, and stability (See also Section 3.3). Thus each NTP server will maintain an estimate of the quality of its reference clocks and of itself.
There are serveral ways how a NTP client will know about NTP servers to use:
| Servers to be polled can be configured manually |
| Servers can send the time directly to a peer |
| Servers may send out the time using multicast or broadcast adresses |
Ideally the reference time is the same everywhere in the world. Once synchronized, there should not be any unexpected changes between the clock of the operating system and the reference clock. Therefore, NTP has no special methods to handle the situation.
Instead, ntpd's reaction will depend on the offset between the local clock and the reference time. For a tiny offset ntpd will adjust the local clock as usual; for small and larger offsets, ntpd will reject the reference time for a while. In the latter case the operation system's clock will continue with the last corrections effective while the new reference time is being rejected. After some time, small offsets (significantly less than a second) will be slewed (adjusted slowly), while larger offsets will cause the clock to be stepped (set anew). Huge offsets are rejected, and ntpd will terminate itself, believing something very strange must have happened.
Naturally, the algorithm is also applied when ntpd is started for the first time or after reboot.
A server operating at stratum 1 belongs to the class of best NTP servers available, because it has a reference clock (See What is a reference clock?) attached to it. As accurate reference clocks are expensive, only rather few of these servers are publically available.
A stratum 1 server should not only have a precise and well-maintained and calibrated reference clock, but also should be highly available as other systems may rely on its time service. Maybe that's the reason why not every NTP server with a reference clock is publically available.
2. Time Exchange
Time can be passed from one time source to another, typically starting from a reference clock connected to a stratum 1 server. Servers synchronized to a stratum 1 server will be stratum 2. Generally the stratum of a server will be one more than the stratum of its reference (See also Q: 5.1.4.1.).
Synchronizing a client to a network server consists of several packet exchanges where each exchange is a pair of request and reply. When sending out a request, the client stores its own time (originate timestamp) into the packet being sent. When a server receives such a packet, it will in turn store its own time (receive timestamp) into the packet, and the packet will be returned after putting a transmit timestamp into the packet. When receiving the reply, the receiver will once more log its own receipt time to estimate the travelling time of the packet. The travelling time (delay) is estimated to be half of "the total delay minus remote processing time", assuming symmetrical delays.
Those time differences can be used to estimate the time offset between both machines, as well as the dispersion (maximum offset error). The shorter and more symmetric the round-trip time, the more accurate the estimate of the current time.
Time is not believed until several packet exchanges have taken place, each passing a set of sanity checks. Only if the replies from a server satisfy the conditions defined in the protocol specification, the server is considered valid. Time cannot be synchronized from a server that is considered invalid by the protocol. Some essential values are put into multi-stage filters for statistical purposes to improve and estimate the quality of the samples from each server. All used servers are evaluated for a consistent time. In case of disagreements, the largest set of agreeing servers (truechimers) is used to produce a combined reference time, thereby declaring other servers as invalid (falsetickers).
Usually it takes about five minutes (five good samples) until a NTP server is accepted as synchronization source. Interestingly, this is also true for local reference clocks that have no delay at all by definition.
After initial synchronization, the quality estimate of the client usually improves over time. As a client becomes more accurate, one or more potential servers may be considered invalid after some time.
NTP uses UDP/IP packets for data transfer because of the fast connection setup and response times. The official port number for the NTP (that ntpd and ntpdate listen and talk to) is 123.
There was a nice answer from Don Payette in news://comp.protocols.time.ntp, slightly adapted:
The NTP timestamp is a 64 bit binary value with an implied fraction point between the two 32 bit halves. If you take all the bits as a 64 bit unsigned integer, stick it in a floating point variable with at least 64 bits of mantissa (usually double) and do a floating point divide by 2^32, you'll get the right answer.
As an example the 64 bit binary value:
00000000000000000000000000000001 10000000000000000000000000000000equals a decimal 1.5. The multipliers to the right of the point are 1/2, 1/4, 1/8, 1/16, etc.To get the 200 picoseconds, take a one and divide it by 2^32 (4294967296), you get 0.00000000023283064365386962890625 or about 233E-12 seconds. A picosecond is 1E-12 seconds.
In addition one should know that the epoch for NTP starts in year 1900 while the epoch in UNIX starts in 1970. Therefore the following values both correspond to 2000-08-31_18:52:30.735861
UNIX: 39aea96e.000b3a75 00111001 10101110 10101001 01101110. 00000000 00001011 00111010 01110101 NTP: bd5927ee.bc616000 10111101 01011001 00100111 11101110. 10111100 01100001 01100000 00000000
When polling servers, a similar algorithm as described in Q: 5.1.3.3. is used. Basically the jitter (white phase noise) should not exceed the wander (random walk frequency noise). The polling interval tries to be close to the point where the total noise is minimal, known as Allan intercept, and the interval is always a power of two. The minimum and maximum allowable exponents can be specified using minpoll and maxpoll respectively (See Q: 5.1.5.1.). If a local reference clock with low jitter is selected to synchronize the system clock, remote servers may be polled more frequently than without a local reference clock in recent version of ntpd. The intended purpose is to detect a faulty reference clock in time.[1]
3. Performance
For a general discussion see Section 3. Also keep in mind that corrections are applied gradually, so it may take up to three hours until the frequency error is compensated (see Figure 3).
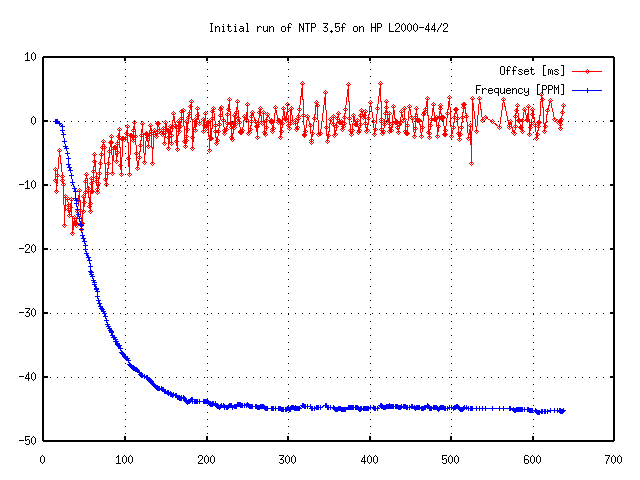
Of course the final achievable accuracy depends on the time source being used. Basically, no client can be more accurate than its server. In addition the quality of network connection also influences the final accuracy. Slow and non predictable networks with varying delays are very bad for good time synchronization.
A time difference of less than 128ms between server and client is required to maintain NTP synchronization. The typical accuracy on the Internet ranges from about 5ms to 100ms, possibly varying with network delays. A recent survey[2] suggests that 90% of the NTP servers have network delays below 100ms, and about 99% are synchronized within one second to the synchronization peer.
With PPS synchronization an accuracy of 50�s and a stability below 0.1 PPM is achievable on a Pentium PC (running Linux for example). However, there are some hardware facts to consider. Judah Levine wrote:
In addition, the FreeBSD system I have been playing with has a clock oscillator with a temperature coefficient of about 2 PPM per degree C. This results in time dispersions on the order of lots of microseconds per hour (or lots of nanoseconds per second) due solely to the cycling of the room heating/cooling system. This is pretty good by PC standards. I have seen a lot worse.
Terje Mathisen wrote in reply to a question about the actual offsets achievable: "I found that 400 of the servers had offsets below 2ms, (...)"
David Dalton wrote about the same subject:
The true answer is: It All Depends.....
Mostly, it depends on your networking. Sure, you can get your machines within a few milliseconds of each other if they are connected to each other with normal 10-Base-T Ethernet connections and not too many routers hops in between. If all the machines are on the same quiet subnet, NTP can easily keep them within one millisecond all the time. But what happens if your network get congested? What happens if you have a broadcast storm (say 1,000 broadcast packets per second) that causes your CPU to go over 100% load average just examining and discarding the broadcast packets? What happens if one of your routers loses its mind? Your local system time could drift well outside the "few milliseconds" window in situations like these.
As time should be a continuous and steady stream, ntpd updates the clock in small quantities. However, to keep up with clock errors, such corrections have to be applied frequently. If adjtime() is used, ntpd will update the system clock every second. If ntp_adjtime() is available, the operating system can compensate clock errors automatically, requiring only infrequent updates. See also Section 5.2 and Q: 5.1.6.1..
NTP maintains an internal clock quality indicator. If the clock seems stable, updates to the correction parameters happen less frequent. If the clock seems instable, more frequent updates are scheduled. Sometimes the update interval is also termed stiffness of the PLL, because only small changes are possible for long update intervals.
There's a decision value named poll adjust that can be queried with ntpdc's loopinfo command. A value of -30 means to decrease the polling interval, while a value of 30 means to increase it (within the bounds of minpoll and maxpoll). The value of watchdog timer is the time since the last update.
ntpdc> loopinfo offset: -0.000102 s frequency: 16.795 ppm poll adjust: 6 watchdog timer: 63 s
Recent versions of ntpd (like 4.1.0) seem to update the correction values less frequently, possibly causing problems. Even if the reference time sources are polled more frequently, the local system clock is adjusted less often.
While in theory estimates of the clock error are maintained, there were practically some software bugs that made these numbers questionable. For example the new kernel clock model dealing with nanosecond resolution (nanokernel) produced overly optimistic estimates regarding the clock offset. The bug has been fixed in August 2000, but also different versions of the NTP daemon may produce different estimates for the same hardware.
The limit actually depends on several factors, like speed of the main processor and network bandwidth, but the limit is quite high. Terje Mathisen once presented a calculation:
2 packets/256 seconds * 500 K machines -> 4 K packets/second (half in each direction).
Packet size is close to minimum, definitely less than 128 bytes even with cryptographic authentication:
4 K * 128 -> 512 KB/s.
So, as long as you had a dedicated 100 Mbit/s full duplex leg from the central switch for each server, it should see average networks load of maximim 2-3%.
4. Robustness
The stratum is a measure for synchronization distance. Opposed to jitter or delay the stratum is a more static measure. Basically (and from the perspective from a client) it is the number of servers to a reference clock. So a reference clock itself appears at stratum 0, while the closest servers are at stratum 1. On the network there is no valid NTP message with stratum 0.
A server synchronized to a stratum n server will be running at stratum n + 1. The upper limit for stratum is 15. The purpose of stratum is to avoid synchronization loops by preferring servers with a lower stratum.
In a synchonization loop the time derived from one source along a specific path of servers is used as reference time again within such a path. This may cause an excessive accumulation of errors is is to be avoided. Therefore NTP uses different means to accomplish that:
The Internet address of a time source is used as reference identifier to avoid duplicates. The reference identifier is limited to 32 bits however.
The stratum as described in Q: 5.1.4.1. is used to form an acyclic synchronization network.
More precisely[2], the algorithm finds a shortest path spanning tree with metric based on synchronization distance dominated by hop count. The reference identifier provides additional information to avoid neighbor loops under conditions where the topology is changing rapidly. This is a very well known problem with algorithms such as this. See any textbook on computer network routing algorithms. Computer Networks by Bertsekas and Gallagher is a good one.
In IPv6 the reference ID field is a timestamp that can be used for the same purpose.
5. Tuning
The default polling value after restart of NTP is the value specified by minpoll. The default values for minpoll and maxpoll are 6 (64 seconds) and 10 (1024 seconds) respectively.
For xntp3-5.93e the smallest and largest allowable polling values are 4 (16 seconds) and 14 (4.5 hours) respectively. For actual polling intervals larger than 1024 seconds the kernel discipline is switched to FLL mode.
For ntp-4.0.99f the smallest and largest allowable polling values are 4 (16 seconds) and 17 (1.5 days) respectively. These values come from the include file ntp.h. The revised kernel discipline automatically switches to FLL mode if the update interval is longer than 2048 seconds. Below 256 seconds PLL mode is used, and in between these limits the mode can be selected using the STA_FLL bit.
Actually there is none: Short polling intervals update the parameters frequently and are sensitive to jitter and random errors. Long intervals may require larger corrections with significant errors between the updates. However there seems to be an optimum between those two. For common operating system clocks this value happens to be close to the default maximum polling time, 1024s. See also Q: 5.1.3.1..
6. Operating System Clock Interface
In order to keep the right time, xntpd must make adjustments to the system clock. Different operating systems provide different means, but the most popular ones are listed below.
Basically there are four mechanisms (system calls) an NTP implementation can use to discipline the system clock (For details see the different RFCs found in Table 4):
settimeofday(2) to step (set) the time. This method is used if the time if off by more than 128ms.
adjtime(2) to slew (gradually change) the time. Slewing the time means to change the virtual frequency of the software clock to make the clock go faster or slower until the requested correction is achieved. Slewing the clock for a larger amount of time may require some time, too. For example standard Linux adjusts the time with a rate of 0.5ms per second.
ntp_adjtime(2) to control several parameters of the software clock (also known as kernel discipline). Among these parameters are:
Adjust the offset of the software clock, possibly correcting the virtual frequency as well
Adjust the virtual frequency of the software clock directly
Enable or disable PPS event processing
Control processing of leap seconds
Read and set some related characteristic values of the clock
hardpps() is a function that is only called from an interrupt service routine inside the operating system. If enabled, hardpps() will update the frequency and offset correction of the kernel clock in response to an external signal (See also Section 6.2.4).
5.2. The Kernel Discipline
- 1. Basic Functionality
- 2. Alternatives
- 3. Monitoring
- 4. PPS Processing
- 5.2.4.1. What is PPS Processing?
- 5.2.4.2. How is PPS Processing related to the Kernel Discipline?
- 5.2.4.3. What does hardpps() do?
1. Basic Functionality
NTP keeps precision time by applying small adjustments to to system clock periodically (See also Q: 5.1.6.1.). However, some clock implementations do not allow small corrections to be applied to the system clock, and there is no standard interface to monitor the system clock's quality.
Therefore a new clock model is suggested that has the following features (See also [RFC 1589]):
Two new system calls to query and control the clock: ntp_gettime() and ntp_adjtime()
The clock keeps time with a precision of one microsecond.[3] In real life operating systems there are clocks that are much worse.
Time can be corrected in quantities of one microsecond, and repetitive corrections accumulate.[3] The UNIX system call adjtime() does not accumulate successive corrections.
The clock model maintains additional parameters that can be queried or controlled. Among these are:
- A clock synchronization status that shows the state of the clock machinery (e.g. TIME_OK).
- Several clock control and status bits that control and show the state of the machinery (e.g. STA_PLL). This includes automatic handling of leap seconds (when announced).
- Correction values for clock offset and frequency that are automatically applied.
- Other control and monitoring values like precision, estimated error and frequency tolerance.
Corrections to the clock can be automatically maintained and applied.
Applying corrections automatically within the operating system kernel does no longer require periodic corrections through an application program. Unfortunately there exist several revisions of the clock model that are partly incompatible. See Section 6.4.1.
If you can find an include file named timex.h that contains a structure named timex and constants like STA_PLL and STA_UNSYNC, you probably have the kernel discipline implemented. To make sure, try using the ntp_gettime() system call.
The following guidelines were presented by Professor David L. Mills:
Feedback loops and in particular phase-lock loops and I go way, way back since the first time I built one as part of a frequency synthesizer project as a grad student in 1959 no less. All the theory I could dredge up then convinced me they were evil, nonlinear things and tamed only by experiment, breadboard and cut-and-try. Not so now, of course, but the cut-and-try still lives on. The essential lessons I learned back then and have forgotten and relearned every ten years or so are:
Carefully calibrate the frequency to the control voltage and never forget it.
Don't try to improve performance by cranking up the gain beyond the phase crossover.
Keep the loop delay much smaller than the time constant.
For the first couple of decade re-learns, the critters were analog and with short time constants so I could watch it with a scope. The last couple of re-learns were digital with time constants of days. So, another lesson:
There is nothing in an analog loop that can't be done in a digital loop except debug it with a pair of headphones and a good test oscillator. Yes, I did say headphones.
So, this nonsense leads me to a couple of simple experiments:
First, open the loop (kill ntpd). Using ntptime,; zero the frequency and offset. Measure the frequency offset, which could take a day.
Then, do the same thing with a known offset via ntptime of say 50 PPM. You now have really and truly calibrated the VFO gain.
Next, close the loop after forcing the local clock maybe 100 ms offset. Watch the offset-time characteristic. Make sure it crosses zero in about 3000 s and overshoots about 5 percent. That with a time constant of 6 in the current nanokernel.
In very simple words, step 1 means that you measure the error of your clock without any correction. You should see a linear increase for the offset. step 2 says you should then try a correction with a fixed offset. Finally, step 3 applies corrections using varying frequency corrections.
2. Alternatives
Despite of the features described in Q: 5.2.1.1. there are reasons to disable the use of the kernel discipline. Especially for very long polling intervals (see also Q: 5.1.5.1.) there are disadvantages with the kernel discipline designed for NTP version 3. Professor David L. Mills said:
The key to the daemon loop performance is the use of the Allan intercept to weight the PLL/FLL contributions. The result is to weight the FLL contributions more heavily with the longer poll intervals. However, the effects are noticeable mostly in the transition region between 256 s and the Allan intercept, which is dynamically estimated as a function of phase noise. All this could be implemented in the kernel discipline, but it doesn't seem worthwhile in view of the very mintor performance that could be achieved. The correct advice in these cases is to avoid the kernel loop entirely if you expect to allow intervals much over 1024 s. (...)
Basically it means that ntpd performs more complex computations than the kernel clock does. Floating point operations are generally avoided in operating system kernels. As mentioned in Q: 5.1.5.2., there's a polling interval where the total error is minimal. This is what is called Allan intercept above.
In NTP version 3 that point was hardcoded as 1024 seconds. For shorter polling intervals PLL mode was used, while for longer intervals FLL mode was used. NTP version 4 has a mixed model where PLL and FLL both contribute to the estimated correction value. However, this does not mean that the older kernel code fails; I successfully ran a standard Linux kernel with maxpoll 17, and the polling interval actually reached 36 hours.[4]
3. Monitoring
Most of the values are described in Q: 6.2.4.2.1.. The remaining values of interest are:
- time
The current time.
- maxerror
The maximum error (set by an application program, increases automatically).
- esterror
The estimated error (set by an application program like ntpd).
- offset
The additional remaining correction to the system clock.
- freq
The automatic periodic correction to the system clock. Positive values make the clock go faster while negative values slow it down.
- constant
Stiffness of the control loop. This value controls how a correction to the system clock is weighted. Large values cause only small corrections to be made.
- status
The set of control bits in effect. Some bits can only be read, while others can be also set by a privileged application. The most important bits are:
- STA_PLL
The PLL (Phase Locked Loop) is enabled. Automatic corrections are applied only if this flag is set.
- STA_FLL
The FLL (Frequency Locked Loop) is enabled. This flag is set when the time offset is not believed to be good. Usually this is the case for long sampling intervals or after a bad sample has been detected by xntpd.
- STA_UNSYNC
The system time is not synchronized. This flag is usually controlled by an application program, but the operating system may also set it.
- STA_FREQHOLD
This flag disables updates to the freq component. The flag is usually set during initial synchronization.
4. PPS Processing
During normal time synchronization, the time stamps of some server are compared about every 20 minutes to compute the required corrections for frequency and offset. With PPS processing, a similar thing is done every second. Therefore it's just time synchronization on a smaller scale. The idea is to keep the system clock tightly coupled with the external reference clock providing the PPS signal.
PPS processing can be done in application programs (see also Q: 6.2.4.5.1.), but it makes much more sense when done in the operating system kernel. When polling a time source every 20 minutes, an offset of 5ms is rather small, but when polling a signal every second, an offset of 5ms is very high. Therefore a high accuracy is required for PPS processing. Application programs usually can't fulfil these demands.
The kernel clock model described before also includes algorithms to discipline the clock through an external pulse, the PPS. The additional requirements consist of two mechanisms: Capturing an external event with high accuracy, and applying that event to the clock model. The first is nowadays solved by using the PPS API (Q: 6.2.4.5.1.), while the second is implemented mostly in a routine named hardpps(). The latter routine is called every time when an external PPS event has been detected.
hardpps() is called with two parameters, the absolute time of the event, and the time relative to the last pulse. Both times are measured by the system clock.
The first value is used to minimize the difference between the system clock's start of a second and the external event, while the second value is used to minimize the difference in clock frequency. Normally hardpps() just monitors (e.g. STA_PPSSIGNAL, PPS frequency, stability and jitter) the external events, but does not apply corrections to the system clock.
Figure 4. PPS Synchronization
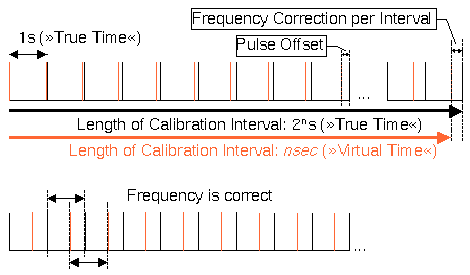
hardpps() can minimize the differences of both, frequency and offset between the system clock and an external reference.
Flag STA_PPSFREQ enables periodic updates to the clock's frequency correction. Stable clocks require only small and infrequent updates while bad clocks require frequent and large updates. The value passed as parameter is reduced to be a small value around zero, and then it is added to an accumulated value. After a specific amount of values has been added (at the end of a calibration interval), the total amount is divided by the length of the calibration interval, giving a new frequency correction.
When flag STA_PPSTIME is set, the start of a second is moved towards the PPS event, reducing the needed offset correction. The time offset given as argument to the routine will be put into a three-stage median filter to reduce spikes and to compute the jitter. Then an averaged value is applied as offset correction.
In addition to these direct manipulations, hardpps() also detects, signals, and filters various error conditions. The length of the calibration interval is also adjusted automatically. As the limit for a bad calibration is ridiculously high (about 500 PPM per calibration), the calibration interval normally is always at its configured maximum.
5.3. NTP in real Life
- 5.3.1. What if I write my own SNTP Server?
- 5.3.2. Why should I have more than one clock?
- 5.3.3. Does the reference time depend on all configured servers, or is it based on which ever responds first?
- 5.3.4. What happens during a Leap Second?
There is a quote (with partial omissions) on that subject by Professor David L. Mills:
(...) The SNTP specification forbids operation as a server unless a primary server connected to a reference clock. (...)
Running SNTP as a server is probably the single most serious hazard in the universe. You might not agree with the particular engineering design in my clock mitigation and discipline algorithms and security model but it is absolutely imperative that the correctness assertions be religiously observed. Even so, folks have come to expect a certain level of performance from the "standard" distribution which the algorithms are designed to achieve. These algorithms have purposely been omitted from the SNTP specification on the understanding that a SNTP server will always have a reference source and a SNTP client will never function as a server to dependent clients.
I've had a lotta years thinking about these models. There should be only two models. One, represented by SNTP, is intended for casual PCs and workstations where simplicity and ubiquity is intended. It has similar functionality as date and rdate and us totally stateless. The other, represented by current NTP, is a widely understood, thoroughly researched and verified engineering design. The design should include a definitive specification and be rigidly implemented to spec so folks have a high level of confidence it does what the spec requires. I want only one such spec, not a plurality of specs and implementations that are not completely interoperable. The NTP subnet is not a community of distinct servers, but a intimately intertwined real-time coupled oscillators. Get one of these things wrong and large portions of the subnet could become unstable. Heck it happens once in a while, notwithstanding the recent bug.
Okay, tune for minimum flame. We are obviously not to that degree of rigor now. There are very, very many places where a definitive spec would contain options - should the huff-'n-puff filter be required? What I have been working on the last few years is to push the envelope to test as many different ideas as feasible and then decide as a group which should be in the core spec and which should be optional.
You may suggest there is nothing wrong with a SNTP subnet of clients and servers which is wholly contained and where synchronization is never leaked to the NTP subnet. I have no problem with this should it be practical. Past experience with undisciplined local clocks leaking to the NTP subnet suggests this will happen with SNTP servers. I don't think it is a good idea to provide a SNTP capability that casually invites newbie folks to disregard the spec. If we really do want to provide such a capability, there should be a serious disclaimer published in conspicuous places. How would it be if a stratum-2 SNTP server sneaked in the list of public servers? (...)
NTP likes to estimate the errors of all clocks. Therefore all NTP servers return the time together with an estimate of the current error. When using multiple time servers, NTP also wants these servers to agree on some time, meaning there must be one error interval where the correct time must be.
Reality[2] suggests that not all NTP servers work as designed in theory. In fact there was a high percentage of stratum-1 servers with a bad time: Over 30% of the active stratum-1 servers had a clock error of over 10 seconds, and a few even had an error of more than a year. The author of the survey says: "Only 28% of the stratum 1 clocks found appear to actually be useful."
Time sources that are reachable and have a dispersion smaller than the maximum become candidates for time synchronization, thus contributing an error interval. In [RFC 1305], section 4.2 the algorithms are treated in greater detail.
If these candidates pass another validation test, they become survivors. Basically all values must lie within the error interval the majority of candidates defines. All other time sources are called falsetickers subsequently.
Among the survivors those with significant high dispersion are removed and tagged as outlyers.
The final synchronization source is the survivor with the smallest dispersion.
From this description, it should be obvious that:
Just one time source will always be trusted
Two time sources cannot be split into two parties where one has a majority.
For a three-server configuration a failing server will cause the two-server problem to appear.
5.3.3. Does the reference time depend on all configured servers, or is it based on which ever responds first?
Neither of these is true. As said in Q: 5.3.2., multiple time sources will be selected and combined to get an estimate of the time. Some criteria are:
Is the configured server reachable, i.e. does it respond to queries?
Do replies of the server satisfy basic sanity checks (delay, offset, jitter (dispersion), stratum)? Basically, lower values are preferred.
If a configured server gets that far, it will be called a candidate. Candidates are ordered by jitter; that one with the lowest jitter will be the new time reference, but all the others will contribute to the estimated time as well.
The theory of leap seconds in explained in Q: 2.4.. In reality there are two cases to consider:
If the operating system implements the kernel discipline described in Section 5.2, ntpd will announce insertion and deletion of leap seconds to the kernel. The kernel will handle the leap seconds without further action necessary.
If the operating system does not implement the kernel discipline, the clock will show an error of one second relative to NTP's time immediate after the leap second. The situation will be handled just like an unexpected change of time: The operating system will continue with the wrong time for some time, but eventually ntpd will step the time. Effectively this will cause the correction for leap seconds to be applied too late.
5.4. Encryption
Providing or enabling the use of encryption in software is considered harmful by the U.S.A.[5] Therefore NTP version 3 was available as export version without DES encryption as well as a non-export version. As xntpd is actually an international product developed and improved allover in the world, NTP version 4 includes no cryptography (from the viewpoint of government regulations).
As MD5 is heavily used in digital signatures, MD5 is not considered as cryptography.