6. Configuration of xntp
ntpdate sets the system clock once and mostly in a brute way. As real clocks drift, you need periodic corrections. Basically can run ntpdate in a cron job hourly or daily, but your machine won't be an NTP server then.
In contrast, running xntpd will learn and remember the clock drift and it will correct it autonomously, even if there is no reachable server. Therefore large clock steps can be avoided while the machine is synchronized to some reference clock. In addition xntpd will maintain error estimates and statistics, and finally it can offer NTP service for other machines. Last, but no least, ntpdate cannot query a local reference clock.
In addition, there are plans to put the functionality of ntpdate into ntpd. Let me quote Professor David L. Mills:
Our zeal to deprecate ntpdate and friends like that is based entirely on our wish to eliminate redundant maintenance. The ntpdate program was crafter many years ago as a ripoff of xntpd with poorly adapted I/O, outdated algorithms and poor debugging support. If we can satisfy folks that ntpd with appropriate command line switch is the answer to their collective prayers, then we will scrap ntpdate and friend. It is in principle easy to modify ntpd to "quickly" set the clock; however, please do understand our reluctance to do that for the following reasons.
Most folks who use ntpdate call it from a cron job at intervals of maybe a day. You would be surprised at how many do this at the stroke of midnight. We have observed little fireballs of congestion when that occurs, especially at the NIST and USNO servers which even in the best of times with polite xntpd/ntpd suffer an aggregate load of well over 40 packets per second. We really don't want clients to create volleys of congestion by transmitting as fast as the network will allow.
The thrust of recent work on the NTPv4 protocols has <not> (with emphasis) been to improve accuracy - the nanokernel development is tangential and the only interlocking agenda has been to adapt the PPS interface to a standard acceptable to the kernel-mongers for the Alpha, SPARC and Intel platforms. However, it is indeed fair to characterize the work specific to NTPv4 as concentrating on the error mitigation algorithms to deal with the extraordinary range of network path characteristics encountered today. There also have been many incremental improvements, such as burst mode, that have resulted from various bug reports and suggestions.
An absolutely vital requirement in our view is to protect against accidental or malicious servers that may result in excessive time errors. The only true defense against falsetickers is to have at least three different servers (a Byzantine defense requires at least four) and an effective mitigation algorithm, such as the one now used in NTP and refined over the last eight years. Note that accuracy is not an issue here, only the separation of the truechimers from the falsetickers.
Now, the first measurement when the ntpd is first started is almost certainly a terrible one. There are many reasons for this - ARP caching in the routers, flow setup at various points and circuit setup (ISDN). The only real solution for that is to use more than one sample. The measurements made some years ago and revealed in an RFC suggest that a window of eight samples is a good compromise between effectiveness (more samples) and closed-loop transient response (fewer samples).
So, I think most folks would agree that some number of different servers is necessary and that some number of samples should be collected before the mitigation algorithms do set the clock. You get to select the former in the configuration file (or use manycast to do that automatically). How many samples to wait before the mitigation algorithms actually set the clock depends on the quality of the estimated accuracy. The parameters selected as the result of experience result in about four samples, depending on the network jitter.
So, let's say that as the result of several years experience and algorithm refinement we agree on four servers and four samples. The question is what is the interval between samples? As delivered from shrinkwrap, the initial interval is 64 s, but does usually increase to 1024 s. That results in about a four minute delay before the clock is set, which might be too long for some, but does protect the musy public servers on the net now. So what's the deal? You can reduce that interval to a few seconds using burst mode. While this does provide more snappy response, it increases the aggregate client insult to the server by a factor of eight and should be used sparingly.
However, this is not the only consideration. When multiple servers are involved, it is not a good idea to poll them at the same time. Therefore, ntpd randomized the initial volley when first coming up. This results in an average delay of about 30 s before anything useful happens. Worse than that, ntpd has to wait until a majority of the configured servers have showed up and with at least four good samples.
You can see from the above why we believe ntpdate is such a poor network citizen and at least some idea of its vulnerabilities. You can also see where the compromises are and possibly how changing some of the parameters might benefit your cause. We could disable the initial randomization, increase the quality tolerance so fewer samples will set the clock, go into burst mode initially and once the clock is set back off to normal mode, etc., etc. Right now, parameter selection is a black art; I would suspect making them configurable will result in some very bad choices and may result in serious server insult. Once upon a time (with NTPv1) a bug resulted in some servers volleying continuously as fast as the net would allow. The bug was discovered only after the network monitoring center reported that NTP was the single largest source of traffic in the Internet.
The issues of whether and how to step the clock have been debated more or less continuously for the twenty years of NTP evolution. One clique believes the clock should never be set backward under any circumstances. Their punishment is to suffer up to some hours while the clock torques to acceptable offset at half a millisecond per second, which is the maximum rate most kernels can tolerate and the limiting assumption which is at the very heart of the formal correctness principles supported by the design. During the torque interval network clocks cannot be assumed synchronized, so network makes, archiving, etc., can fail, even if local applications may survive. The -g option was designed to behave this way, but its use is not recommended.
A complicating fact is that, once an error greater than 125 ms is discovered, the question is whether to believe it. Our experience with radio clocks is that it may take several minutes or more to obtain initial synchronization. This and the fact that very noisy paths to some remote spots on the globe can result in huge spikes from time to time suggest that the clock should not be stepped until a consistent offset has been observed for a sanity interval, currently 15 minutes. Considerable experience suggests this is a good compromise time, but your agenda might be better served using some other value. What should it be?
In the vast majority of cases, once the clock is reliably set and the frequency stabilizes, the clock does not need to be stepped again, even after reboot and sometimes even when the power is cycled. The current NTP behavior is to step the clock if necessary when ntpd is started and the clock has never been set, then to obey the -g option after that. This was done as the result of suggestions made some time back.
Obviously, keeping most folks happy with any one set of rules may not be acceptable by other folks. The intent feverishly pursued is to avoid configured little nits in favor of an adaptive approach where the daemon figures things out on its own and without configured appeasement. It may be possible to satisfy more that some folks crave by continued enhancement and re-engineering of intricate behavior, but the above ground rules must be respected.
(...)
To avoid a biased impression, lets quote Per Hedeland as well:
99.9999% of NTP users don't care one iota whether ntpdate does such a lousy job that the clock ends up just within 50 ms of the correct time instead of 5 or 0.005. On the other hand they care a lot if the boot has to be delayed - for how long? 5 x 64 seconds? - just to allow ntpd to get a good enough fix that it is prepared to step the clock. And they care a lot, though they may not know it, if various applications (which may be many more than "some database servers") run into problems because the clock is stepped after they've started instead of before.
6.1. Basic Configuration
6.1.1. Recommended Minimum
- 6.1.1.1. What is the minimum configuration?
- 6.1.1.2. Is the minimum configuration a typical one?
- 6.1.1.3. What is the correct Pseudo IP Address for my reference clock?
- 6.1.1.4. What is that drift-file?
- 6.1.1.5. Should I use IP addresses or host names?
The minimum configuration for xntpd only needs one reference clock. Reference clocks use pseudo IP addresses in xntpd. Thus your configuration file could look like this:
server 127.127.8.0 mode 5 # GENERIC DCF77 AM
Note: Some reference clock drivers require special device files to be created. These files are used to talk to the reference clock. See the corresponding documentation of the driver (If you take the third number of the address, the documentation is most likely found in a file driver#.htm where # is that number).
In reality one would add several other configuration items, like a drift-file, additional servers, remote monitoring and configuration, logging, access restrictions, etc.
Besides being functional, configurations for the real life look differently from the one shown in question Q: 6.1.1.1.. Most NTP servers have no reference clocks, but use lower stratum servers as time references (See also Q: 5.1.4.1.). Public time servers can be found using the NTP home page. Courtesy suggests to inform the maintainers of the time server that you are using their service (See also What is the preferred etiquette when synchronizing to a public server?). As an advantage, they might inform you if their service is going to be down. There is almost no difference in the configuration:
server 132.199.176.10 # some NTP server's IP address # You might add the EMail address of the contact person
Configuring multiple servers improves the quality of the time. That is because of NTP being able to select the best time sources from a set of available ones. See Why should I have more than one clock? for details.
As seen in Q: 6.1.1.1., the various drivers for reference clocks are selected using IP adresses. Such an IP address consists of four bytes that are separated by a dot.[1] The individual bytes are: 127, 127, Clock Type, Unit Number
File refclock.htm from the software distribution (see Q: 4.3.2.1.) lists the supported clock types. Usually it does not make sense, but if you want to connect more than one clock of a type, you can do so by using different unit numbers. The driver maps these unit numbers to one or more device files. The exact name of the device file can be found in the description of the individual reference clock's driver (drivern.htm).
When running, xntpd learns about the drift of the system clock relative to the reference clock. To make xntpd remember the drift, you must add the following item to your configuration file (it will be updated every hour):
driftfile /etc/ntp.drift # remember the drift of the local clock
When using a drift-file xntpd will use the last written value as initial frequency correction after restart. That way the best correction is set up much faster (Without a drift-file the initial frequency correction is always zero).[2]
During startup xntpd resolves symbolic addresses to numeric addresses using the resolver service. However there are some differences worth considering:
If a symbolic name has assigned multiple IP addresses, you may wish to explicitly select one.
Using numeric addresses does not require a correct configuration of a resolver, and it may avoid making a connection to the Internet.
Many service providers use aliases or logical host names when providing services. When using names like ntp-1-a for an NTP server, the service provider may map the logical name to a different machine, possibly without informing any clients. So if you use host names in your configuration file, all you have to do is to restart or reconfigure (see also Q: 6.1.3.4.) your ntpd.
6.1.2. Running an isolated Network
- 6.1.2.1. Can I use my system clock as reference clock?
- 6.1.2.2. Can I avoid manual time adjustments in a network without reference clock?
In short: You can, but you should not. See also What is LCL, the Local Clock?.
| Warning |
Using the free-running system clock means that your NTP server announces that time as reference time to any client, no matter how wrong it is. Especially when connected to the Internet this can cause severe confusion. |
A recent survey[2] discovered that about 95% of bad stratum-1 servers had configured LCL, the local clock, as time reference. So please don't make the same mistake after having read this!
Care has to be taken if you intend NTP to propagate manual changes of the local system time. xntpd (NTP v3) uses an artificial time scale that will not (immediately) follow such changes. See also Q: 5.1.1.4..
XXX Note from the editor: This issue probably requires further discussion.
If you have a MODEM and you can afford the telephone costs, you can use the following configuration to call NIST (thanks to William R. Pennock):
# NIST Automated Computer Time Service. This driver calls a special # telephone number in Boulder, CO, to fetch the time directly from the # NIST cesium farm. The details of the complicated calling program are # in html/refclock.htm. The Practical Peripherals 9600SA modem # does not work correctly with the ACTS echo-delay scheme for # automatically calculating the propagation delay, so the fudge flag2 is # set to disable the feature. Instead, we add a fudge time1 of 65.0 ms # so that the driver time agrees with th e1-pps signal to within 1 ms. # The phone command specifies three alternate telephone numbers, # including AT modem command prefix, which will be tried one after the # other at each measurement attempt. In this case, a cron job is used to # set fudge flag1, causing a measurement attempt, every six hours. server 127.127.18.1 fudge 127.127.18.1 time1 0.0650 flag2 1 phone atdt813034944774 atdt813034944785 atdt813034944774
6.1.3. Recommended Goodies
- 6.1.3.1. How can I configure the amount of logging information?
- 6.1.3.2. How can I speed up initial Synchronization?
- 6.1.3.3. How do I configure remote administration?
- 6.1.3.4. How do I use authentication keys?
- 6.1.3.5. What are all the different Keys used for?
- 6.1.3.6. How do I use the new autokey feature?
When starting to run xntpd you should have a more verbose logging than set up by default. Before you go into the details, you might start with the following line:
logconfig =syncevents +peerevents +sysevents +allclock
When absolutely clueless of what's going on, you might enable full logging (Make sure your /etc/syslog.conf captures all these messages):
logconfig =all
As explained earlier (see Q: 5.1.2.1.), several packet exchanges are needed before time can be corrected. Therefore the obvious trick is to speed up packet exchanges. See Q: 5.1.2.4. for a general discussion of the polling algorithm. In NTP version 4 a new keyword named iburst can be used to quickly set up the registers of the receive filter when they are empty. Typically this is true for a restart, or when the connection to a server was down for a longer period. When used, the data should be available within 30 seconds.
If the local clock does not have a good estimate for the current time, using option -g on the command line may also speed up the time until ntpd sets the clock for the first time. Furthermore that option will also allow suspiciously huge initial correction.
These modifications are actually intended as a replacement for ntpdate in NTPv4. A script named ntp-wait will wait until ntpd has set the time of the local host for the first time.
One of the nice features of NTP is the ability of remote monitoring and configuration. You can add or remove reference clocks at runtime without having to restart xntpd. Normally this doesn't work until you specify authentication information (you don't want anyone to remove your reference clocks, I guess). Authentication in NTP works with keys. First you'll have to specify the numbers of the keys to be used:
### Authentication section ### keys /etc/ntp.keys trustedkey 1 2 15 requestkey 15 controlkey 15
This tells xntpd to trust keys 1 and 2 when receiving time information. Key 15 is trusted for queries and configuration changes (requestkey is used by xntpdc while controlkey is used by ntpq).
Note: Even though controlkey and requestkey are explicitly specified, you still must add the keys to trustedkey.
To specify the keys for xntpd you'll have to create the file /etc/ntp.keys. As xntpd runs as priviledged process, only the priviledged user (root) needs access to this file.
Note: Password are stored unencrypted in the keyfile. Therefore no other user should have read or write access to that file (or write access to any containing directory).
Here's an example for the contents of a keyfile; the first column specifies the key number (range 1 to 65535), the second column the key type (S (DES key in DES format), N (DES key in NTP format), A (DES key as ASCII string), M (MD5 key as ASCII string)), and the third column is the key itself:
1 S 68767ce625aef123 2 S df2ab658da62237a 15 A I_see! 498 M NTPv4.98
Depending on the type of key (DES or MD5) you want to use, you'll have to use the command keytype in xntpdc to specify the type your key has. Normally you are asked for the key's number and the password when xntpdc uses a command to change the configuration. Your input will be remembered inside xntpdc, so that you only have to enter it once per session.
The example above uses DES keys. DES stands for Data Encryption Standard and is considered as munition in the USA, and therefore may not be exported. Probably as this 56-bit encryption is rather ridiculous to the rest of the world, DES keys are no longer supported in xntp version 4. You would change all the letters in the second column to M. "M" stands for MD5, Message Digest #5, a strong one-way hash function.
The popular implementation of NTP we are talking about has a powerful feature named dynamic reconfiguration. This means you can change the configuration of your servers using the protocol itself. As this works over the network, there's no need to log in or to walk around. Even more, it works the same on all operating systems.
As not everybody should be allowed to change the configuration of an NTP server, configuration items are protected by an authentication algorithm. You have to prove that you are allowed to access configuration items by entering some magic key (read: password). xntpdc automatically asks for a key number and a password when it is required. Once entered, the key and password is remembered:
xntpdc> keytype des xntpdc> unconfig 127.127.8.0 Keyid: 15 DES Password:
While possible, specifying the password on xntpdc's command line like xntpdc -c "keyid 1" -c "passwd pw" -c "other_command" is not recommended.
In addition to the example given in Q: 6.1.3.3., Professor David L. Mills states:
Control keys are for the ntpq program and request keys are for the ntpdc program. The key file(s) define the cryptographic keys, but these must be activated individually using the trustedkey command. That last is so a single key file can be shared among a bunch of servers, but only certain ones used between pairwise symmetric mode servers. You are invited to cut this paragraph and paste it on the refrigerator door if it eases confusion.
NTP version 4 has a new way of managing authentication keys, commonly referred to as autokey mechanism. The following procedure had been given by Professor David L. Mills:
A broadcast server needs to have a line like broadcast 128.4.2.255 autokey
The clients simply have broadcastclient.
Replace broadcast with multicast and follow autokey with ttl 5 or something like that. As for the crypto questions, http://www.eecis.udel.edu/~mills/autokey.htm and briefings from there.
See also Q: 6.2.2.6..
6.1.4. Miscellaneous Hints
- 6.1.4.1. What is the preferred etiquette when synchronizing to a public server?
- 6.1.4.2. How and where can I find public Time Servers?
If the listing at http://www.eecis.udel.edu/~ntp says to notify before before using a server, then you should send email and wait until you get an affirmative reply before using that server.
Some public timeservers are listed as "open access" with no notice required (especially the secondaries). Very public-spirited. I have one of these (stratum-2 right now) at ntp-cup.external.hp.com.
You should probably have no more than three of your timeservers using any individual public timeserver. Let all of your internal clients be served by those three (or three-groups-of-three).
The most popular time servers are highly overloaded, recommending that you should avoid them if possible. The official etiquette is described in http://www.eecis.udel.edu/~mills/ntp/servers.htm, section Rules of Engagement.
Additionally, NIST (the United States National Instute of Standards and Technology) has a list of public time servers at http://www.boulder.nist.gov/timefreq/service/time-servers.html. Their policy statement implies that their Internet time servers are open access to everyone.
6.2. Advanced Configuration
6.2.1. Server Selection
- 6.2.1.1. What is the rule of thumb for number of servers to synchronize to?
- 6.2.1.2. Should the servers be a mix of primary and secondary servers?
- 6.2.1.3. How should I provide NTP services for a huge network?
It is entirely up to you and your tolerance for outages. Obviously you have some tolerance, or you would be buying GPS receivers and installing your own stratum-1 servers. But three is a good place to start, and you can progress to three-groups-of-three if you feel the need. Remember that network outages are at least as likely as timeserver outages, so if you only have one network path to the outside world then adding a lot more timeservers doesn't really improve your reliability (your ISP is the single-point-of-failure).
Probably not. The secondaries are good enough for almost everybody. If you care about the small differences in accuracy/precision between the primaries and the secondaries (and you must be close enough, topology-wise, to even see the difference) then you should buy some GPS receivers.
For a huge network you should provide enough redundancy while avoiding a single point of failure. The following discussion will be based on Figure 5, a configuration that is frequently recommended. I'm not saying it's the only possible configuration, but let's just have a closer look.
Figure 5. Configuration for a huge Network
1a 1b 1c 1d 1e 1f outside . \ / ...... \ / ...... \ / .............. 2a ---p--- 2b ---p--- 2c inside /|\ /|\ /|\ / | \ / | \ / | \ 3a 3b 3c 3e 3f 3g 3h 3i 3j Key: 1 = stratum-1, 2 = stratum-2, 3 = stratum-3, p = peer
The example configuration uses six stratum-1 servers (1a ... 1f) to synchronize three stratum-2 servers (2a ... 2c). All servers at stratum two are peers to each other. Each of these stratum-2 servers serve three stratum-3 servers. Clients will be using the servers at stratum three.
Having more than one reference server configured increases reliability and stability of the client (See Q: 5.3.2.). That is why there are two servers for each of the stratum-2 servers. Distributing time horizontally (peering) reduces the amount of traffic to the stratum-1 servers while giving additional redundancy for the stratum-2 servers. The extra layer of stratum-2 servers helps to distribute the load created by lower levels (stratum-3).
If you have a reference clock, you would probably arrange peering with one or more stratum-1 server. For most networks you can probably leave out the third layer (stratum-3) completely.
There's an additional comment by David Dalton:
But my advice is this: if your stratum-N peers all use the same ISP to get to the outside world, then peers are mostly pointless. Your single-point-of-failure is the network path, not the stratum-1 machines themselves. Building huge redundancy into your hierarchy can get very expensive very quickly. Think hard about how much redundancy you really need.
And another comment from Mark Martinec:
I don't find the Figure 5 a good idea. It has a big problem in that stratum-3 servers in the picture all have a single point of failure in their single reference stratum-2 NTP server, not to mention it throws away all the fancy NTP algorithms.
As a fix (and to make it cleaner/leaner), one could strike out the stratum-3 layer completely from the picture and say that each of the company clients will use all three peered company stratum-2 servers as their reference.
If one really needs more fanout (doubtful), one can put back the stratum-3 layer, but with each stratum-3 server referenced to each of the company stratum-2 servers.
6.2.2. Authentication
- 6.2.2.1. Why Authentication?
- 6.2.2.2. How is Authentication applied?
- 6.2.2.3. How do I create a key?
- 6.2.2.4. How does Authentication work?
- 6.2.2.5. Can I add Authentication without restarting ntpd?
- 6.2.2.6. How do I use Public-Key Authentication (autokey)?
Most users of NTP do not need authentication as the protocol contains several filters against bad time. However, there is still authentication, and its use seems to become more common. Some reasons might be:
You only want to use time from trusted sources
An attacker may broadcast wrong time stamps
An attacker disguise as another time server
NTP uses keys to implement authentication. These keys are used when exchanging data between two machines. As shown in Q: 6.1.3.3. and Q: 6.1.3.4., one of the uses has to do with remote administration. When configuring a server or peer, an authentication key can be specified.
In general, both parties need to know the keys. The keys residing in /etc/ntp.keys typically are unencrypted and thus should be hidden from public.[3] This means, the keys have to be distributed to all communication partners in a secure way. The following example is derived from html/notes.htm:
peer 128.100.49.105 key 22 peer 128.8.10.1 key 4 peer 192.35.82.50 key 6 # path for key file keys /usr/local/etc/ntp.keys trustedkey 4 6 14 15 22 # define trusted keys requestkey 15 # key (7) for accessing server variables controlkey 15 # key (6) for accessing server variables authdelay 0.000094 # authentication delay (Sun4c/50 IPX)
The keyword key specifies the key to be used when talking to the specified server. You must trust the key to synchronize time. As authentication involves extra computing, the keyword authdelay specifies this amount of time. In newer versions this calculation is done automatically, while older distributions have a utility named authspeed to determine this number for DES or MD5.
An A key is just a sequence of up to eight ASCII characters (some characters with special meaning can't be used).
An M key is a sequence of up to 31 ASCII characters.
An S key is a 64 bit value with the low order bit of each byte being odd parity.
An A key is a 64 bit value with the high order bit of each byte being odd parity.
Now that you know the basics for keys, use a key as good as a password. For an example with some valid keys see Q: 6.1.3.3.. More information can be found in html/confopt.htm and html/notes.htm.
Basically authentication is a digital signature, and no data encryption (if there is any difference at all). The usual data packet plus the key is used to build a non-reversible magic number that is appended to the packet. The receiver (having the same key) does the same computation and compares the result. If the results match, authentication suceeded.
Yes and No: You can dynamically add servers that use authentication keys, and you can trust or un-trust any key using xntpdc. You can also re-read the keyfile using the readkeys command. Unfortunately you need basic authentication before using any of these commands (see Q: 6.1.3.3.).
The following material is mostly from an article by J�rgen Georgi, based on release 4.0.99k (autokey v1, rsaref20).[4]
You need extra RSA libraries (like rsaref. See README.rsa for instructions.
You need the utility ntp_genkeys to generate key-pairs and the Diffie-Hellman parameters file. All generated files have a timestamp suffix, it is recommended to install a symlink from the default name (without the timestamp extension) to the actual file:
$ ntp_genkeys Generating MD5 key file... Generating RSA public/private key pair (512 bits)... Generating Diffie-Hellman parameters (512 bits)... $ ls ntp.keys.3174020162 ntpkey_dh.3174020162 ntpkey.3174020162 ntpkey_nops.BelWue.DE.3174020162 $ ln -s ntp.keys.3174020162 ntp.keys $ ln -s ntpkey.3174020162 ntpkey $ ln -s ntpkey_dh.3174020162 ntpkey_dh $ ln -s ntpkey_nops.BelWue.DE.3174020162 ntpkey_nops.BelWue.DE
In this example, nops.BelWue.DE is the canonical name of the local host. It is automatically appended to the file names by ntp_genkeys. File ntpkey_nops.BelWue.DE contains the public RSA key of host nops.BelWue.DE. File ntpkey contains the private RSA key. Needless to say that ntpkey and ntp.keys must not be world readable.
Create a configuration file ntp.conf and a directory structure like this:
crypto keysdir /etc/ntp/ keys /etc/ntp/ntp.keys ... server noc1.belwue.de autokey version 4 server noc2.belwue.de autokey version 4 server rustime01.rus.uni-stuttgart.de version 3 peer nepi.BelWue.DE autokey version 4 ...
/etc/ntp/ /etc/ntp/leap-seconds.3169152000 /etc/ntp/ntp.keys -> ntp.keys.3174020162 /etc/ntp/ntp.keys.3174020162 /etc/ntp/ntpkey -> ntpkey.3174020162 /etc/ntp/ntpkey.3174020162 /etc/ntp/ntpkey_dh -> ntpkey_dh.3174020906 /etc/ntp/ntpkey_dh.3174020906 /etc/ntp/ntpkey_leap -> leap-seconds.3169152000 /etc/ntp/ntpkey_nepi.BelWue.DE -> ntpkey_nepi.BelWue.DE.3174020497 /etc/ntp/ntpkey_nepi.BelWue.DE.3174020497 /etc/ntp/ntpkey_nops.BelWue.DE -> ntpkey_nops.BelWue.DE.3174020162 /etc/ntp/ntpkey_nops.BelWue.DE.3174020162
File leap-seconds.3169152000 was downloaded from ftp://time.nist.gov/pub/. File ntpkey_nepi.BelWue.DE is the public RSA key of peer nepi.BelWue.DE. File ntpkey_dh is the same with all authenticated associations, it must be shared among all clients and servers of a security compartment. It does not matter on which host it was generated. You see that the public RSA keys for to the other two authenticated servers are missing. They autokey mechanism is able to download these keys from the servers over the net.
If authentication is working, your should have output similar to this:
ntpq> pe remote refid st t when poll reach delay offset jitter ============================================================================== LOCAL(1) LOCAL(1) 6 l 58 64 377 0.000 0.000 0.000 +noc1.belwue.de .DCFp. 1 u 415 1024 377 2.071 4.886 0.020 +noc2.belwue.de .DCFp. 1 u 520 1024 377 1.936 4.891 0.016 *rustime01.rus.u .DCFp. 1 u 422 1024 377 3.855 3.829 0.037 -nepi.BelWue.DE rustime01.rus.u 2 u 259 1024 376 1.839 8.957 0.217 ntpq> as ind assID status conf reach auth condition last_event cnt =========================================================== 1 57740 9014 yes yes none reject reachable 1 2 57741 f4f4 yes yes ok candidat reachable 15 3 57742 f4f4 yes yes ok candidat reachable 15 4 57743 9634 yes yes none sys.peer reachable 3 5 57744 f334 yes yes ok outlyer reachable 3 ntpq> rv status=06f4 leap_none, sync_ntp, 15 events, event_peer/strat_chg, version="ntpd 4.0.99k-r Thu Jul 27 15:41:30 MET DST 2000 (7)", processor="sun4u", system="SunOS5.6", leap=00, stratum=2, precision=-15, rootdelay=3.855, rootdispersion=25.972, peer=57743, refid=rustime01.rus.uni-stuttgart.de, reftime=bd4d0006.7ba24894 Tue, Aug 22 2000 15:35:02.482, poll=10, clock=bd4d01be.a8915bdd Tue, Aug 22 2000 15:42:22.658, state=4, phase=4.548, frequency=7.357, jitter=1.913, stability=0.016, hostname="nops.BelWue.DE", publickey=3174020162, params=3174020906, refresh=3175878685, leaptable=3169152000, tai=32
Let's add a final quote from J�rgen Georgi: "This setup works with ntp-4.0.99k. I could not get it working with 4.0.99i. If my description contains errors, please let me know."
See also Q: 6.1.3.6.. For those interested in the details, let's quote Professor David L. Mills: "The latest Autokey draft is at http://www.ietf.org/internet-drafts/draft-ietf-stime-ntpauth-04.txt. Almost all the cryptographic means is in ./ntpd/ntp_crypto.c in the latest distribution. (...)"
6.2.3. Broadcasting, Multicasting, and Manycasting
- 1. Broadcasting
- 6.2.3.1.1. How do I configure a Broadcast Server?
- 6.2.3.1.2. How do I configure a Broadcast Client?
- 6.2.3.1.3. Why doesn't Broadcasting work with LCL?
- 2. Multicasting
- 3. Manycasting
- 6.2.3.3.1. What is Manycasting at all?
1. Broadcasting
A line like broadcast 128.4.2.255 enables periodic sending of broadcast packets containing the current time as long as the server's clock is synchronized. The period may be influenced by the minpoll option. Packet forwarding can be limited by specifying the ttl option. Make sure you are using the correct broadcast address for your subnet.
For the client use a line containing broadcastclient.
Using the line broadcastclient will enable listening to broadcasts. As anybody can send out any broadcasts, use of authentication is strongly advised. In version 3 you would have to define the broadcastdelay to compensate the network delay. In version 4 the client actively will query a broadcasting server to calibrate the delay. More details can be found in file html/assoc.htm (Association Management).
Before continuing, make sure you read and understood Q: 7.1.1. and Q: 6.1.2.1.. As you shouldn't broadcast bad time, a prefer keyword is required when using LCL.
3. Manycasting
This is an explanation by Professor David L. Mills: "Manycast only works in multicast mode. It uses an expanding-ring search by adjusting the TTL field. This doesn't make sense in broadcast mode, since broadcast packets do not span subnets. It might in fact be useful to implement manycast in broadcast mode without the search, but that is rather far down the to-do list." (...) "Only the * and + tattletales indicate a candidate survivor. Note that one of your servers is in process of going away, another coming onboard. This is a normal situation when first coming up and when the signatures are refreshed once per day. I assume you are using autokey; if not, no promises at all."
So basically it's a mechanism to automatically configure servers on a nearby network. Compared to broadcasting and multicasting, manycasting uses the normal server keyword, but with a multicast group address (class D) on the client. Manycast servers use the keyword manycastserver. As for broadcasts and multicasts, manycast associations on the client may come and go over time.
6.2.4. PPS Synchronization
As stated before, network connections suffer from random delays. Even for local reference clocks the exact point in time to which some time message belongs is difficult to determine. Delays imposed by the operating system is another issue to deal with.
Therefore some means to improve the situation were thought of:
The operating system could be modified to capture the time of some external event more precisely. Among such events could be characters received at a serial port or some signal edge detected on a digital input.
If such external events arrive periodically with high precision, the time stamps could be used to determine the frequency error of the associated computer clock.
If the external event arrived exactly at the time when a new second starts, the time stamps could be used to correct the offset of the associated computer clock.
Basically this is what all the PPS discussion is about. So let's add some questions.
- 1. Before you start
- 2. Verification
- 3. Special Drivers
- 6.2.4.3.1. What is that ATOM or PPS peer?
- 6.2.4.3.2. How do I use PPS with the Motorola Oncore driver?
- 6.2.4.3.3. How do I use PPS with NMEA driver
- 4. Configuration
- 6.2.4.4.1. What changes are required in ntp.conf?
- 5. Software Interfaces
- 6.2.4.5.1. What is that PPS API?
- 6. Hardware Interfaces
1. Before you start
The following items are needed in oder to use PPS synchronization:
You need a high precision signal that can be connected to the computer running NTP. Usual sources of such PPS signals are quality reference clocks that feature such an output.
Your operating system must support processing of PPS signals. Most operating systems that come with source code (such as Linux and FreeBSD) can be modified to support PPS processing. As a matter of fact someone else probably did it already so you just need to install and configure the software.
Most operating systems supporting PPS do not only have some programming interface to read timestamps, but they also implement the NTP kernel clock model with special PPS processing options. See also Q: 5.2.4.3..
The NTP software must also be configured to recognize and use PPS processing. Usually the software's autoconfigure process will detect the presence of PPS processing capabilities.
Finally you should prepare your configuration file ntp.conf to work with PPS.
2. Verification
6.2.4.2.1. So I think I have all required components ready, how will I see that everything is working?
The pleasant part of this answer is that there are tools included in the standard NTP software that makes this an easy task. The less pleasant part is that there is no single way to enable PPS detection for each operating system. However the new PPS API (see Q: 6.2.4.5.1.) may change things in a positive way.
Let's start with the easier part using standard tools:
There are two means to look at the NTP kernel clock: ntptime and ntpdc -c kerninfo. As ntptime is a little more verbose, let's consider it.
windl@elf:~ > ntptime ntp_gettime() returns code 0 (OK) time bd6b9cf2.9c3c6c60 Thu, Sep 14 2000 20:52:34.610, (.610297702), maximum error 3480 us, estimated error 0 us. ntp_adjtime() returns code 0 (OK) modes 0x0 (), offset 1.658 us, frequency 17.346 ppm, interval 128 s, maximum error 3480 us, estimated error 0 us, status 0x2107 (PLL,PPSFREQ,PPSTIME,PPSSIGNAL,NANO), time constant 6, precision 3.530 us, tolerance 496 ppm, pps frequency 17.346 ppm, stability 0.016 ppm, jitter 1.378 us, intervals 57, jitter exceeded 29, stability exceeded 0, errors 0.
The above command has been run on Linux version 2.2.16 with PPSkit-1.0.0. That combination features PPS processing and a kernel clock using nanoseconds.
The first thing you should look at is the status (0x2107 in our case). The magic words in parentheses explain the meaning of the individual bits. The important bit for now is PPSSIGNAL. That bit is set directly by the operating system and says a PPS signal has been detected.
Now that pulses are detected, let's see whether they are good ones. For that purpose we read some additional numbers about the kernel clock's calibration process:
intervals 57 says that there were 57 calibration intervals. When PPS pulses are arriving, this number should increase. Each frequency adjustment requires a good calibration interval. The length of the current calibration interval can be found as interval 128 s (128 seconds is the default maximum length). Remaining numbers count abnormal conditions as explained below.
jitter exceeded 29 means that there were 29 pulses that arrived at a time when they were not considered good (However, completely bad pulses are not counted here). This can mean that the pulses were out of range, or that the system clock was read badly when the pulses arrived. The algorithm dynamically adjusts the threshold for jitter. Occasional jitter is allowed and should not worry you. If significant jitter is detected, the flag PPSJITTER is set in addition.
stability exceeded 0 is the number of calibration intervals that would result in a correction larger than considered valid (The default limit quite high).
Validity is a bit fuzzy here, but it means that the frequency change would be more than the tolerance. You can find the tolerance coded into your operating system from tolerance 496 ppm, but it's not guaranteed that the value is specific to your hardware.
Stability should not be exceeded during normal operating conditions. Upon detection of that error the flag PPSWANDER is set.
Finally errors 0 indicates the number of calibration intervals where pulses were missing or completely out of bounds. In these cases the flag PPSERROR is set. During normal operation that number should not increase.
Those numbers are only reset when the machine is booted.
If you did not find an error so far, your PPS configuration should work! You can inspect some additional performance indicators:
stability 0.016 ppm is an averaged value for the last frequency corrections made (actually it's an instability). Basically a small value indicates that both, your operating system's clock, and your external PPS signal are stable. As mentioned before, temperature changes affect the average PCs a lot (See also Q: 5.1.3.1.). The sample above was taken after running the system for about one hour; you should expect a value below 0.1 ppm for a stable system.
jitter 1.378 us is also an averaged value. It indicates how much the individual pulses vary from second to second (as measured by the operating system's clock). This value will vary due to system load and interrupt latency. A few microseconds are probably fine, but a few milliseconds definitely are not!
This completes the basic checks for PPS configuration. In the case above the NTP daemon is also working and using the data provided from the operating system kernel. I'll complete the description of the remaining output:
pps frequency 17.346 ppm indicates the current correction value for the clock frequency derived from the PPS signal. Positive values indicate that your clock is too slow compared to the PPS. If flag PPSFREQ is set, that frequency correction is used for correcting the kernel clock. The NTP daemon will set this flag if the PPS parameters seem valid.
offset 1.658 us shows the last measured offset correction for the system clock. If flag PPSTIME is set, that offset is derived from the offset of the PPS pulse every second, and otherwise it's updated through ntp_adjtime() from the application. A positive value for offsetmeans that the system clock is behind the reference time.
PPS pulses add further corrections while the kernel clock tries to consume this offset by correcting the time accordingly. Formerly the offset was updated every 16 seconds by the kernel, but recently it's updated every second.
3. Special Drivers
Even when the kernel clock uses PPS signals to calibrate, the NTP daemon will still use the usual offsets of some reference clock. As it is desirable to use the offsets of the PPS pulses, there is a pseudo clock driver to do that. That driver needs to know the interface specific to the platform to get the time stamps of the PPS pulses.
That driver is called ATOM or PPS, and it can be configured just as any other reference clock. The difference is that PPS can only be used in combination with another preferred time reference. As soon as the preferred time reference is used for synchronization, the ATOM driver becomes reachable, and it will eventually be used as primary synchronization source (See also Why should I have more than one clock?). A PPS peer will be handled specially so that other time offsets are not considered. The command ntpq -c peer -c as -c rl will print something like:
remote refid st t when poll reach delay offset jitter ============================================================================== +GENERIC(1) .GPS. 0 l 48 64 377 0.000 0.025 0.001 oPPS(1) .PPS. 0 l 17 64 377 0.000 0.027 0.000 ind assID status conf reach auth condition last_event cnt =========================================================== 1 57300 9434 yes yes none candidat reachable 3 2 57301 9714 yes yes none pps.peer reachable 1 status=2194 leap_none, sync_atomic/PPS, 9 events, event_peer/strat_chg, version="ntpd 4.0.99k Sun Sep 10 19:22:28 MEST 2000 (5)", processor="i586", system="Linux2.2.16-NANO", leap=00, stratum=1, precision=-16, rootdelay=0.000, rootdispersion=1.831, peer=57301, refid=PPS, reftime=bd6b94f2.272b8844 Thu, Sep 14 2000 20:18:26.153, poll=6, clock=bd6b952d.da89dadf Thu, Sep 14 2000 20:19:25.853, state=4, phase=0.005, frequency=16.984, jitter=0.000, stability=0.043
Considering the configuration below, John Hay wrote:
(...)The Oncore driver directly manages the PPS stuff, so you only need the first line (server 127.127.30.0 prefer) in the config file. The rest is not needed to have a functional Oncore refclock.
Some options like the flag3 and enable pps stuff is remnants of the xntp3 days I think and isn't used by ntp4 anymore. The "pps ..." line is only useful for drivers like the NMEA driver, that don't manage the PPS signals themselves, but use the global serial port access routines and even in that case the line must precede the server line for the same device in the config file.
server 127.127.30.0 prefer fudge 127.127.30.0 stratum 0 server 127.127.22.1 # ATOM(PPS) fudge 127.127.22.1 flag3 1 # enable PPS module pps /dev/oncore.pps.0 assert hardpps # PPS device
Note: As documented in PPS Clock Discipline (driver8.htm) of ntp-4.1.1a, flag2 controls the edge of the PPS signal being used. Thus the pps keyword seems obsolete by now.
Maybe it should also be noted here that a site survey can take significant time to finish. Terje Mathisen says: "My survey (under Linux) took about 36 hours, I also gave up a couple of times before allowing it to run to completion."
In NTP versions after 4.0.99k23 is NMEA driver atomized what means that for PPS processing we don't need neither ATOM driver nor PPS command in ntp.conf.
Here is sample ntp.conf:
server 127.127.20.0 # NMEA driver fudge flag3 1 # enable kernel PPS discipline
4. Configuration
Unfortunately PPS processing is a little messy (see also What is that PPS API?). Nevertheless I'll give an example that works.
Example 4. Using a PPS Signal
This example works for ntp-4.0.99k together with PPSkit-1.0.0 on my Linux PC. I'll only show the significant parts of /etc/ntp.conf[5] .
pps /dev/refclock-1 assert hardpps # PPS device (ntpd-4.0.97 and above) server 127.127.8.1 mode 135 prefer # Meinberg GPS167 with PPS fudge 127.127.8.1 time1 0.0042 # relative to PPS for my hardware server 127.127.22.1 # ATOM(PPS) fudge 127.127.22.1 flag3 1 # enable PPS API
When starting, the following things happen:
The clock GENERIC(1) becomes reachable while PPS is used to update the kernel variables described in Q: 6.2.4.2.1..
The configured clock is selected as synchronization source, and status changes to 0x2143 after a while. At that time PPS(1) also becomes reachable. During that time status changes to 0x2107, and offset shows current offsets from PPS.
Eventually PPS(1) becomes PPS peer.
5. Software Interfaces
As seen above, the programming interface specific to the operating system and platform is a messy thing. Therefore some people decided to make a common programming interface named PPS API. In March 2000 that draft was accepted as an informational RFC (See Table 4 for related RFCs). The functions of the API include:
Routines to enable capturing of external events on a specified device (if supported).
Routines to query the last captured time stamps and associated event counters.
Routines to change operating parameters like compensating processing delays, select polarity of the PPS signal, etc.
Routines to control automatic processing of detected events by a kernel consumer in the kernel of the operating system.
As the API is still quite new, there are only very few implementations ([RFC 2783] says: "Several available implementations of this API are listed at http://www.ntp.org/ppsapi/PPSImpList.html. Note that not all of these implementations correspond to the current version of the specification.").[6]
Internet-Drafts are draft documents valid for a maximum of six months and may be updated, replaced, or obsoleted by other documents at any time. It is inappropriate to use Internet-Drafts as reference material or to cite them other than as "work in progress."
The list of current Internet-Drafts can be accessed at http://www.ietf.org/ietf/1id-abstracts.txt.
6. Hardware Interfaces
That depends. The higher the quality your serial port is, the longer pulses will be needed. This is because of the ESD protection of the chip.
26 usec should be about the bit time for a 38400 serial line, so you could connect it to the RxD line instead and see if you receive characters that way when the port is set for 38400 or faster.
Another thing to try is to configure the serial port for 115200, some of the chips base their deglitching on the baud rate, often requiring a full symbol before they react.
6.2.5. Automatic Configuration
- 1. BOOTP
1. BOOTP
The BOOTP protocol is defined in [RFC 1048] (obsoleted by [RFC 2132]). Marc Brett contributed:
Time ([RFC 868]) servers may be specified in the Vendor Extensions field, Code 4.
Network Time Protocol (NTP) ([RFC 1305]) servers may be specified in the Application and Service Parameters, Code 42.
In some popular bootpd, time servers are specified with ts=, but NTP servers are specified with nt=. The latter allows a list of Internet addresses to be specified.
If you are using Microsoft Windows or Macintosh, you have to check whether your DHCP client software or your NTP software contains such a feature already. If not, you are probably out of luck.
If you are using a UNIX system, you may be able to install the needed code yourself. Of course, exactly what is needed depends on your particular software, but if you are comfortable editing the initialization scripts, it shouldn't be too hard.
In general, UNIX systems implement BOOTP/DHCP via a client daemon which handles the interaction with the DHCP server. But often, the daemon does not itself set up the network interface's address or do any other work based on the DHCP reply. Instead, it stores the information in some suitable place, and activates an initialization script to use that information to adjust the computer's configuration.
Your first job is to identify the correct script. Start by tracking down the script that brings up the interface during normal startup. That script will have code which activates the DHCP client, and thus must also arrange to activate the script that implements the configuration provided by DHCP.
For instance, in RedHat Linux 8.0, a network interface is brought up by /etc/sysconfig/network-scripts/ifup, which calls the DHCP client (/sbin/dhclient) at line 188. When dhclient receives a response from the DHCP server, it executes a program specified by the "-sf" argument, or by default, /sbin/dhclient-script. It is that script which adjusts the computer's configuration. In this case, the script is already set up (line 152) to change ntp.conf if the DHCP server provides NTP server information.
In RedHat Linux 7.x, a network interface is also brought up by /etc/sysconfig/network-scripts/ifup, which calls the DHCP client (/sbin/pump or /sbin/dhcpcd) near line 127. We see from the dhcpcd(8) manual page that dhcpcd revises resolv.conf itself (unless "-R" is specified), but that other DHCP configuration information can be implemented by the script /etc/dhcpc/dhcpcd-interface.exe.
6.2.6. Offering Time Service
- 6.2.6.1. My NTP Server has a number of IP Addresses for different Nets. Is there any way to request ntpd to attach to a specific Interface?
- 6.2.6.2. Should Access be restricted?
- 6.2.6.3. What should be done before announcing public NTP service?
6.2.6.1. My NTP Server has a number of IP Addresses for different Nets. Is there any way to request ntpd to attach to a specific Interface?
As far as I know, ntpd attaches to all interfaces. What happens if you have virtual adresses (interface aliases) depends on the operating system. For some operating systems ntpd listens to all adresses.
It is known that the issue is handled sub-optimal, and it's being worked on it...
First, well, if you don't want to have clients, don't offer the service. But as you want to offer NTP service to others, you should not be afraid of clients. Let me quote from an article in news://comp.protocols.time.ntp written by David Dalton about the subject whether queries with ntpq and ntpdc should be allowed:
I am somewhat new to the security concerns of public timeservers. Only in the past few weeks did I upgrade my public timeserver at 192.6.38.127 to stratum-1 with a Trimble Palisade GPS receiver. It doesn't have a lot of security right now, but the "xntpdc" reconfiguration functions are restricted. I'm soliciting advice about how to protect myself, although I don't depend on that public timeserver in any way.
I agree with you that there is no substitute for long-term data for evaluating the stability of a timeserver (and the network between yourself and the timeserver).
But the query tools allow one to make evaluations without spending a lot of time, because the timeservers themselves have already collected the long-term data. I always want to run "ntpq -p" or "xntpdc -p" on a remote timeserver before committing to it. Very handy.
Even long-term statistics (gathered by your own client) won't tell you anything about how well the remote server is configured. How many reference clocks does it have? Which reference clocks? How many stratum-1 servers does it have in case the clock(s) fail(s)? Which one of these candidates would you prefer?
EXAMPLE ONE (BAD) ----------------- [444]ntpq -p fubar.net remote refid st t when poll reach delay offset disp ========================================================================= *WWVB_SPEC .WWVB. 0 l 18 16 377 0.00 0.301 1.69 LOCAL(1) LOCAL(1) 0 l 1 16 377 0.00 0.000 10.01 EXAMPLE TWO (NOT BAD) --------------------- [170]ntpq -p fubar2.net remote refid st t when poll reach delay offset disp ========================================================================= *WWVB_SPEC( .WWVB. 0 l 30 16 377 0.00 0.140 2.01 LOCAL(1) LOCAL(1) 10 l 13 16 377 0.00 0.000 10.01 +hpxxxxxxxx .GPS. 1 u 11 16 376 0.99 -0.708 0.35 +hpxxxxxxxx .GPS. 1 u 49 64 377 4.97 -2.680 0.81 hpxxxxxxxx xxxxxxxx 3 u 206 1024 377 4.70 -3.010 9.69 hpxxxxxxxx xxxxxxxx 3 u 29 1024 377 2.88 -4.287 0.17 EXAMPLE THREE (OUTSTANDING) --------------------------- [169]ntpq -p ntp2.usno.navy.mil remote refid st t when poll reach delay offset disp ========================================================================= +GPS_VME(0) .USNO. 0 l 15 16 377 0.00 -0.007 0.02 *GPS_VME(1) .USNO. 0 l 14 16 377 0.00 0.003 0.02 +GPS_VME(2) .USNO. 0 l 13 16 377 0.00 0.028 0.02 +tick.usno .USNO. 1 u 45 64 376 1.65 0.032 0.64 -tock.usno .USNO. 1 u 16 64 377 1.48 -0.072 0.47 x204.34.19 .USNO. 1 u 24 64 377 226.88 3.924 1.77 x204.34.19 .USNO. 1 u 1014 1024 376 249.76 10.737 26.49 navobs1.g 0.0.0.0 16 - - 1024 0 0.00 0.000 16000.0
That article continues:
You and I might agree that a handheld consumer-grade GPS receiver putting out NMEA data to a small workstation (unix or WinNT) with 500 milliseconds dispersion is a poor excuse for a stratum-1 public timeserver, but that doesn't stop somebody from offering such a server for public use. No sanity checking or evaluation is done on the machines listed at UDelaware (AFAIK).
Here is what my handheld GPS receiver (400 dollars) looked like:
[179]ntpq -p gpstime.net remote refid st t when poll reach delay offset disp ========================================================================= *GPS_NMEA .GPS. 0 l 1 64 377 0.00 -226.243 420.08Here is a stratum-2 timeserver that has a good pedigree (HP-UX) and is synching to a stratum-1 timeserver that has an HP GPS clock, but the stratum-2 machine is having problems because the network is _very_ congested (and it has no backup sources):
remote refid st t when poll reach delay offset disp ========================================================================== big_srv 17.8.5.7 2 u 3 512 17 312.87 -249.15 1960.85Here are some results from well configured public timeservers that I have surveyed at various times. It is interesting to work your way through the stratum-1 list at UDelaware and see a lot of timeservers this way.
[165]ntpq -p ntp-cup.external.hp.com remote refid st t when poll reach delay offset disp ========================================================================= *REFCLK(29,1) .GPS. 0 l 21 32 377 0.00 0.014 0.02 +bigben.cac.wash .USNO. 1 u 115 128 377 38.48 -0.292 0.46 +clepsydra.dec.c .GPS. 1 u 2 128 377 6.94 0.044 0.21 -clock.isc.org .GOES. 1 u 381 1024 377 6.29 -3.159 0.11 hpsdlo.sdd.hp.c bigben.ash 2 u 25 32 125 53.68 -9.817 3.69 -tick.ucla.edu .USNO. 1 u 70 128 377 19.18 -0.894 0.38 -usno.pa-x.dec.c .USNO. 1 u 39 128 377 7.05 -0.434 0.26
So there are valid arguments for allowing some standard queries from prospective or active NTP clients. On the other hand there are also arguments for restricting access:
Configuration changes (see also How do I use authentication keys?) should be restricted to machines within the own administrative domain at least.
You might consider the possibility that a security hole is found in some software, and that that hole could be exploited to do bad things to your server. Therefore you could restrict or enable certain ranges of IP addresses.
As with any service offered in the Internet, there is a potential to do something stupid. You are strongly advised to do some monitoring of your server before going public (See Section 8.1).
Once you are satisfied with the performance data, you should also consider the following questions:
Does my server have an offset and stability better or equal to other servers at the same stratum?
Does my server have redundant or highly available time sources (reference clocks or peers)?
Did you arrange peering with at least one other server at the same or at an even better stratum?
Do I want to serve possibly hundreds of clients, most of them unknown to me?
Can my connection to the Internet satisfy the demands for NTP service (good network response times and very few dropped packets)?
Is the server machine highly available (Does it start up automatically after a failure), and is there a contact person in case of problems?
Are there plans to continue the service for at least six months?
If you answered any of the preceeding questions with "No", you should re-consider your decision of offering public time service.
6.3. Various Tricks
Note: Mixing different time protocols is generally deprecated, because it can invalidate some assumptions necessary for proper operation of any time protocol.
1. Mixing Time Protocols
The short and possibly unpleasant answer is: "Run NTP on that server!".
Of course you need a modified configuration to prevent clock adjustments originating from NTP. Maybe let's see an example (thanks to Marc Brett):
Example 5. Using TimeServ and NTP on Windows/NT
Some Windows/NT servers are using TimeServ for clock synchronization, one checks the USNO clock via modem. You also want to synchronize some UNIX servers, but NTP via Internet is not possible.
Configure NTP on your Windows/NT server according to the following:
server 127.127.1.0 fudge 127.127.1.0 stratum 4 driftfile %windir%\ntp.drift disable ntp
disable ntp will prevent NTP from adjusting the local clock.
2. Avoiding Time Steps
6.3.2.1. I'd like to correct my System Clock by some larger Amount, but Time Steps are not acceptable. Any ideas?
(Answer by Marc Brett) NTP works with up to 1000 seconds of offset, but when the error is "big", where big is defined as 128 ms (!), it will by default step the clock.
It is possible to tell it to always slew the clock though.
However, in your case I would suggest another possibly simpler method:[7]
Install ntpd V4, with no reference clocks except the local clock (127.127.0.1), fudge stratum to 10 or something like that.
Make a fake ntp.drift file containing a value which would correct for your drift rate (about -10.0), plus a value big enough to bring it back in line within a week: -(20 * 60) * 1e6 / (86400 * 7) = -1984
Since this number is too large (greater than 500 ppm), I suspect that you'll have to settle for using -500 in ntp.drift, and allow up to four weeks for your clock to be approximately correct of slightly slow.
(I believe a negative number in ntp.drift will indeed slow the clock down, can anyone verify this?)
At that time you can insert a proper NTP server in your ntp.conf file and restart the daemon.
An alternative solution suggests (I assume that there is a chance of simply taking the server offline for 30 minutes sometime during the next few weeks):
Shutdown
Set the BIOS clock
Restart
3. Measuring and Calibrating
This answer provided by Vladimir Smotlacha was rephrased by the editor.
For example, the Linux implementation of the PPS API contains the echo feature for the serial ports. The principle is quite simple: An event on the DCD line causes the interrupt routine to generate an event also on the RTS line after getting the event's timestamp. With some external device like a two channel oscilloscope or counter one can measure difference between original signal and its echo. About the half of the time is the delay between creation of the event and getting its timestamp. That way one can estimate the delay and jitter between real PPS signal and its timestamps.
An utility named ppsctl (formerly named enable_pps) can be used to activate echo on a port by additionally specifying -eX, where X is either a (assert) or c (clear). The utility just sets the flags as described in [RFC 2783]. The Linux implementation will always clear the RTS bit in the UART if an event becomes active, and it will clear the bit when the DCD line changes back to the inactive state. Therefore you cannot have an echo for both events.
Example 6. Measurements and Statistics of PPS Echo Delay
The following graphs are result of PPS echo delay measurement during normal operation of an NTP server (about 120 clients). The first PC is a standard Pentium 150MHz (UDMA disk, kernel 2.2.17, NTP 4.0.99k), the second is DELL 1400 (Pentium III 860MHz, SCSI disk, kernel 2.2.18, NTP 4.0.99k36). Source of PPS signal was a Garmin GPS35, and a universal counter SR 620 (Stanford Research Systems) was used for measurements.[8]
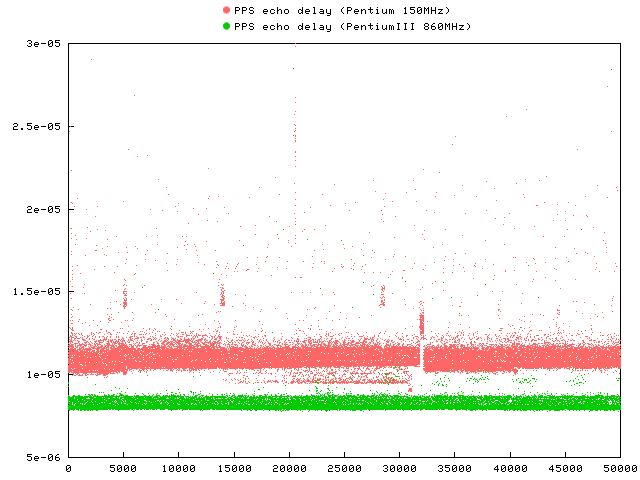
The graph shows the raw measurements for the delay round-trip time.
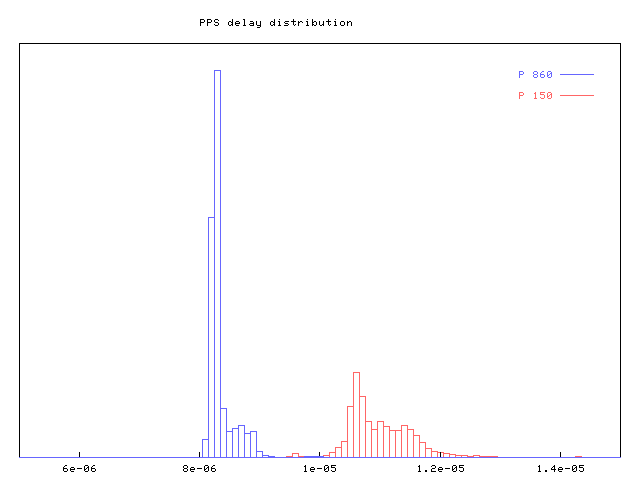
The graph shows the distribution of the delay samples.
When varying the system load for the P150, a kernel compilation (varying I/O and CPU load), the delay incresed by roughly 15 microseconds. Plain CPU load (simple loop) only add an extra delay of 7us, while disk I/O add up to 30us. IDE disks without using DMA add up to 100us of extra delay.
6.4. Compatibility
6.4.1. The Kernel PLL
- 6.4.1.1. How many different kernel models and implementations do exist?
- 6.4.1.2. What's new in each Version?
- 6.4.1.3. Are the individual kernel models compatible?
- 6.4.1.4. How can I find out which kernel is in effect?
- 6.4.1.5. Is the Linux implementation different?
There are definitely at least two major versions for the kernel PLL: The model for NTP version 3, and the model for NTP version 4. Maybe there is a model for older versions too, but I don't know.
In addition to these major versions there are minor variants of these models. Unfortunately these minor variants can't easily be distinguished, because their inventor and chief designer, Professor David L. Mills, did not like version control systems or version numbers in the past (see also Q: 6.4.1.4.).
As said in Q: 6.4.1.1. the history of the earlier kernel clock models are somewhat obscure. The basic features are described in Q: 5.2.1.1..
The new clock model designed during development of NTP version 4 has the following new features:
Timestamps are represented with 64 bit (instead of 32) to represent a sub-nanosecond resolution. There is also a new interface to control these nanoseconds. The higher precision results in a more continuous flow of time.
A new status bit, STA_MODE, controls a hybrid PLL/FLL mode, avoiding instabilities.
The minimum interval between adjustments has been reduced from 16 seconds to one second, while the maximum interval has been extended from about one hour to 36 hours. Unfortunately constant has an incompatible meaning (See Q: 6.4.1.3.).
PPS processing has been significantly revised as well. The calibration range has been extended, and the robustness towards spikes and jitter has been improved. Sampling intervals have been reduced to achieve a faster response to offset and frequency errors.
Revision 3 of the nanokernel introduced a shorter default calibration interval when correcting the frequency with PPS. At the same time the maximum interval can be adjusted using MOD_PPSMAX. Selection of PLL and FLL mode is done automatically now.
Revision 4 of the nanokernel features more direct response to PPS offset errors, more realistic error estimates, and a new mode bit (MOD_TAI) to define the offset between UTC and TAI.
A later revision of featured a longer default calibration interval for PPS and a partial state reset when STA_PLL is cleared.
The most recent version known as nanokernel has different semantics for the time_constant. When used with the old version 3 daemon, the PLL has a tendency to oscillate, because the damping is too low.
When the old kernel implementation is used with the new version 4 daemon, the PLL is too stiff, causing a slow adjustment to frequency changes.
When the new version 4 daemon has set the STA_NANO bit, the old version 3 daemon gets completely confused by nanoseconds which are believed to be microseconds. As it seems, the daemon does not clear STA_NANO during startup, so the only solution is to reboot or clear that flag by other means.
Professor David L. Mills wrote:
The old and new kernel code does use different time constant ranges. The current ntpd and API do understand and adjust accordingly. The old xntpd will probably be off by a factor of 16 in the time constant. That is absolutely certain to cause unstable operation.
If you have an even older implementation, you probably can't compile the daemon, or the daemon will not use the kernel PLL.
As indicated before, this is not quite easy. Maybe the following procedure can help you.
If #include <sys/timex.h> defines the symbol NTP_API you are lucky. This symbol appeared in the kernel simulator dated 1999-08-28, and the symbol's value was 3 there. So any newer version should define a different value. It's quite unlikely that older implementations define the same symbol set to a smaller value.
If #include <sys/timex.h> defines the symbol STA_NANO you may have the newer clock model for NTPv4. See step 1.a for further steps.
If you still had no success with this procedure, you have a kernel implementation for NTPv3 or even older.
If your NTP_API is set to 4 or higher, the following procedure may identify the sub-releases:
When the default upper limit for the PPS calibration interval is 256 seconds (not 128 seconds), and the length of the calibration interval is reset to 4 seconds whenever STA_PLL makes a one-to-zero transition, you have a nanokernel revision of at least 2000-10-25.
Otherwise your revision is from 2000-08-29 or older.
XXX Note from the editor: The procedures above can probably be improved. Contributions welcome!
Yes, it is. One reason is that the original nanokernel found (after it had been said to work well and be stable) was broken considering STA_PPSWANDER. According to Professor David L. Mills the current nanokernel is no longer showing that defect. As I was not aware of that change, I did something different.
Professor David L. Mills wrote: "MAXWANDER is 100 in the current nanokernel, not 500. This value was adjusted due to simulation experience."
When used with a PPS signal, the Linux implementation (as of PPSkit-0.7) also computes uncommon values for tolerance as I explained to Professor David L. Mills:
Secondly my code starts out at 500 PPM (because that's what the nanokernel simulator used that I had). Only if a PPS signal is active and within bounds (pps_shift >= 5 in my case, rather arbitrary), I watch the interval of PPS frequencies and make the maximum width of that interval the new "tolerance" (clamped at 500 PPM, of course). Then I use that value of tolerance as limit for the "wander". As the first interval is quite narrow (close to zero), the calibration interval will get stuck at 2^5 seconds if the frequency adjustment increases, or maybe even it will be reduced until the wander either within the current bounds. Only if the calibration interval is at its minimum possible length with a desire to decrease still, the wander will be adjusted (otherwise you might end with a maximum wander of 1 PPM and the PPS frequency will bump up and down by that limit).
In PPSkit-0.9 the tolerance appears as fixed 496 ppm, but the maximum of the observed wander is still computed and used internally. It is used to advance the maximum error by a more reasonable amount.
Another feature is that the maximum error is limited in Linux: It's either 16s or 2s, depending on your version of the kernel. Whenever that value is reached, the STA_UNSYNC flag is set in the kernel clock.