8. Troubleshooting
8.1. Monitoring
Without any doubt, troubleshooting requires monitoring. Somehow you must find out that something is wrong before you wonder how to fix it.
- 8.1.1. If I think my NTP server is working fine, what could I do to confirm this?
- 8.1.2. How do I use peerstats and loopstats?
- 8.1.3. How can I see the Time Difference between Client and Server?
- 8.1.4. What does 257 mean as value for reach?
- 8.1.5. What can I use these statistics files for?
One of the quickest commands to verify that ntpd is still up and running as desired is ntpq -p. That command will show all peers used and configured together with their corner performance data.
As the above command requires periodic invocation to monitor the performance, it is also recommended to enable statistic files in ntpd. See also Q: 8.1.2. and Q: 8.1.3..
I use the following lines in /etc/ntp.conf to enable loopfilter statistics (See the line starting with statistics). New files are created every day, and the current files are available as /var/log/ntp/peers and /var/log/ntp/loops. Older files are archived as /var/log/ntp/peers.YYYYMMDD and /var/log/ntp/loops.YYYYMMDD:
statistics loopstats statsdir /var/log/ntp/ filegen peerstats file peers type day link enable filegen loopstats file loops type day link enable
Usually I only monitor the loops file. Table 3 lists the individual fields of each file. I'll show examples for peerstats and loopstats for version 3 and 4 in the following screens.
Table 3. Statistic Files
| File Type | Version | List of Fields |
|---|---|---|
| loopstats | 3 | day, second, offset, drift compensation, polling interval |
| 4 | day, second, offset, drift compensation, estimated error, stability, polling interval | |
| peerstats | 3 | day, second, address, status, offset, delay, dispersion |
| 4 | day, second, address, status, offset, delay, dispersion, skew (variance) |
50560 73386.259 127.127.8.1 9695 -0.001186 0.00000 0.00961 50560 73450.260 127.127.8.1 9695 -0.002161 0.00000 0.00528 50560 73514.261 127.127.8.1 9695 -0.003087 0.00000 0.00333
50560 73386.259 -0.001186 16.8701 6 50560 73450.260 -0.002161 16.8619 6 50560 73514.374 -0.003087 16.8501 6 50560 73578.295 -0.003959 16.8350 6
51801 71273.247 127.0.0.1 2194 0.000000609 0.000000000 0.000001023 0.000000000 51801 71273.248 127.127.22.1 9714 0.000001290 0.000000000 0.000000000 0.000000018 51801 71304.037 127.127.8.1 9434 0.000000879 0.000000000 0.000000000 0.000000032 51801 71339.248 127.127.22.1 9714 -0.000000076 0.000000000 0.000000000 0.000000028 51801 71368.038 127.127.8.1 9434 -0.000000129 0.000000000 0.000000000 0.000000046
(By Terje Mathisen) Normally ntpd maintains an estimate of the time offset. To inspect these offsets, you can use the following commands:
- ntpq -p will display the offsets for each reachable server in milliseconds (ntpdc -p uses seconds instead).
- ntpdc -c loopinfo will display the combined offset in seconds, as seen at the last poll. If supported, ntpdc -c kerninfo will display the current remaining correction, just as ntptime does.
The first can be used to check what ntpd thinks the offset and jitter is currently, relative to the preferred/current server, the second can tell you something about the estimated offset/error all the way to the stratum 1 source. Q: 8.1.2. describes a way to collect such data automatically.
If a PPS source is active (see Q: 5.2.4.1. and Section 6.2.4), the offset displayed with the second choice is updated periodically, maybe every second.
Sometimes things are wrong and you may want to compare time offsets directly. An easy way is to use ntpdate -d server to compare the local system time with the time taken from server.
(Inspired by Martin Burnicki) The value displayed in column reach is octal, and it represents the reachability register. One digit in the range of 0 to 7 represents three bits. The initial value of that register is 0, and after every poll that register is shifted left by one position. If the corresponding time source sent a valid response, the rightmost bit is set.
During a normal startup the registers values are these: 0, 1, 3, 7, 17, 37, 77, 177, 377
Thus 257 in the dual system is 10101111, saying that two valid responses were not received during the last eight polls. However, the last four polls worked fine.
You can do a lot of useful things with statistic files before you remove them. For example there is a utility named summary.pl written in Perl to compute mean values and standard deviation (RMS) from the loopfilter and peer statistics. It will also show exceptional conditions found in these files. Here's a short example output (you could have used summary.pl --dir=/var/log/ntp --start=19990518 --end=19990604):
loops.19990518 loop 110, -30+/-36.5, rms 6.7, freq 14.95+/-1.149, var 0.612 loops.19990519 loop 113, -26+/-40.3, rms 6.9, freq 12.95+/-3.240, var 1.378 loops.19990520 loop 107, -7+/-32.0, rms 5.7, freq 13.04+/-3.253, var 1.579 loops.19990522 loop 190, 3+/-18.5, rms 2.9, freq 15.48+/-3.715, var 0.604 loops.19990523 loop 146, -5+/-9.2, rms 1.9, freq 15.77+/-0.716, var 0.305 loops.19990604 loop 73, -27+/-29.8, rms 6.9, freq 16.81+/-0.327, var 0.140
Still another utility named plot_summary.pl can be used to make plots with these summary data. As an alternative you could plot the loopfilter file directly with gnuplot[1] using the command plot "/var/log/ntp/loops" using 2:3 with linespoints. Figure 6 had been produced with a little more complicated command. It shows yerrorbars with the estimated errors for offset and frequency respectively.
Figure 6. Plot of estimated Offset and Frequency Error (DCF77)
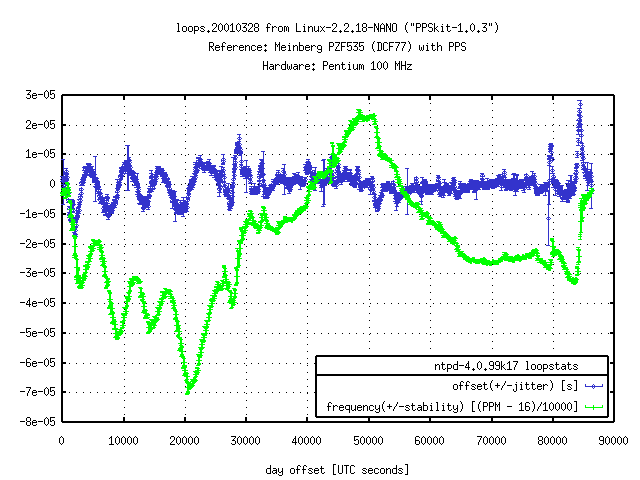
The reference clock, the antenna, and the computer system were located in an office room without air condition.
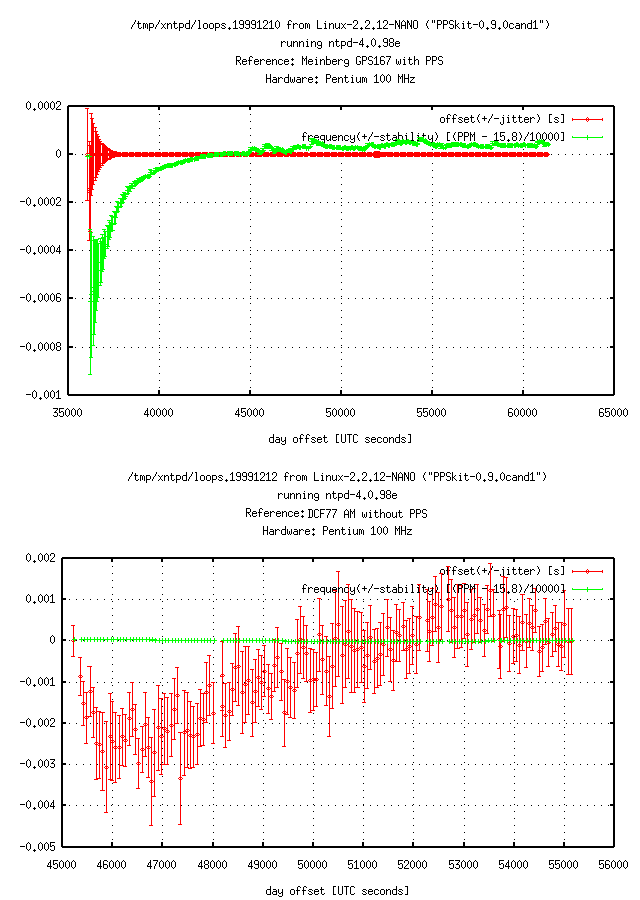
Now that we are looking at numbers and graphs, let us compare the data of a GPS clock (using PPS) with a typical low-cost clock (not using PPS). Figure 7 shows a very small offset for the GPS clock. The frequency is continuously adjusted. In comparison, the DCF77 clock shows a high variation for the offset, but the frequency is adjusted less drastically (Figure 6 shows values between those, using a better DCF77 receiver with PPS).
8.2. General Issues
- 1. Starting, running, querying
- 2. Cabling and Interfacing
- 3. Exchanging Time
- 4. Time Errors
- 5. Messing with broken Hardware
- 6. Incompatibilities
- 8.2.6.1. How do I set the precision?
- 7. Other...
1. Starting, running, querying
The easiest command to verify that xntpd is still running is ntpq -p. This command will contact xntpd on the local host, and it will list all configured servers together with some health status. If xntpd is not running, the typical error message is ntpq: read: Connection refused.
If your are logged in to a UNIX machine, you can use the ps to look for the daemon.
8.2.1.2. Whenever I execute ntpd the daemon will only run for about 10 to 20 minutes. Do you have any idea why?
ntpd expects that the system time has been set closely to the real time, for example by using ntpdate. If the reference time is significantly off, ntpd waits up to 20 minutes until it sets the time (See also Q: 5.1.1.4.).
However, if the time is off by more than some magic amount of roughly 20 minutes, ntpd refuses to set the system time, and it terminates instead. To confirm what is going on, look into syslog or into the logfile you configured!
Either set your system clock with ntpdate before starting ntpd, or try the -g switch for ntpd. Or just set the time manually.
2. Cabling and Interfacing
Sometimes drivers misinterpret the meaning of DCD to be a MODEM status. When using the stty -a command, the port used should have clocal set (preferrably together with -hupcl). When using a standard modem cable, make sure that the DCD pin is not connected to some other output of the reference clock as well.
First, the PPS API is not required to provide an implementation that can detect both edges of a pulse. See function time_pps_getcap() in the description of the API.
Then the hardware may not be responding fast enough. See also Q: 6.2.4.6.1. about timing on a serial port.
Finally, even if the hardware can send an interrupt for the edge being detected first, the CPU may be still busy with handling the interrupt when the hardware detects the other edge. That may either cause the second interrupt to be missed, or the interrupt handler being called for the first interrupt actually sees a hardware state that corresponds to the second interrupt condition, thereby reporting the wrong event, ignoring the edge that originally triggered the interrupt.
3. Exchanging Time
Basically the procedure to check a remote server is identical to debugging a local server, but some commands may be restricted. To check a remote server with ntpq, simply add the desired host name or IP address to the command line.
There is another command named ntptrace to follow a complete synchronization path from the local or specified server to the reference clock.
Example 7. Using ntptrace
This example is taken from David Dalton's NTP Primer, another good introduction to NTP (originally written for HP-UX):
ntptrace cosl4 cosl4: stratum 5, offset 0.022003, synch distance 0.24033 te897-01.cup.hp.com: stratum 4, offset 0.014292, synch distance 0.17822 hpuxps.cup.hp.com: stratum 3, offset 0.006833, synch distance 0.13556 cupertino.cns.hp.com: stratum 2, offset 0.005313, synch distance 0.07320 listo.hp.com: stratum 1, offset 0.010896, synch distance 0.02277, refid 'WWVB'
The output of the command shows the stratum of the desired server, the estimated offset from the correct time, and an estimation of the random error.
Well, this is the answer for the impatient: Probably you have made no mistakes, but you simply have to wait for about five minutes until the server synchronizes to a time reference for the first time. If you changed the minpoll parameter, the wait time may change accordingly.
If you are running xntpd for the first time, you may even have to wait longer, because xntpd resets after a time step, thus needing another five minutes. (see also How will NTP discipline my Clock?).
If the above does not apply, see the next question.
If you have waited for more than 20 minutes since startup of xntpd, it's time for monitoring xntp. First you should verify that your daemon is still running (see Q: 8.2.1.1.). In any case you should also check your syslog for messages from xntpd. Messages found there are influenced by the logconfig statement in /etc/ntp.conf and by your /etc/syslog.conf.
If you still have no clue of what's going wrong, you should contact xntpd with one of the frontend programs named ntpq and xntpdc. One of the easiest ways to get a first impression of the daemon's status is:
Run ntpq -p on the host where xntpd is running, or specify the host name at the end of the command line for a remote host (e.g. ntpq -p hostname). This command will show you the number and the status of your configured or otherwise used time references.
Run ntpq -c as in a similar way to see what xntpd thinks of these time references.
If the above does not explain your problem, use ntpq -p to quickly inspect configured time sources, reachability, delay, and dispersion. Basically the reachability should be 377 for full reachability (an octal value). The delay should be positive, but small, depending on your network technology. Dispersion should be below 1000 (1 second) for at least one server. One of the servers should be marked with a *.
Here's another example taken from David Dalton's NTP Primer (NTPv3):
remote refid st t when poll reach delay offset disp ========================================================================= *WWVB_SPEC(1) .WWVB. 0 l 114 64 377 0.00 37.623 12.77 relay.hp.com listo 2 u 225 512 377 6.93 34.052 10.79 cosl4.cup.hp.co listo 2 u 226 512 377 4.18 29.385 13.21 paloalto.cns.hp listo 2 u 235 512 377 9.80 33.487 11.61 chelmsford.cns. listo 2 u 233 512 377 88.79 30.462 9.66 atlanta.cns.hp. listo 2 u 231 512 377 67.44 32.909 12.86 colorado.cns.hp listo 2 u 233 512 377 43.70 30.077 18.63 boise.cns.hp.co listo 2 u 224 512 377 33.42 31.682 8.54
4. Time Errors
Ideally the quality of a time reference is a static feature. In reality however they can be of varying quality over time. In addition you should realize that the observed quality can have the two reasons already mentioned in My server periodically loses synchronization.
In fact this behaviour is so frequent that it has a name of its own: clock hopping
Clock hopping can be avoided by deterministic network delays, but usually you can't do anything about that. The other solution is to select a preferred time source that is used as long as it seems reasonable (even if other sources have better quality). To do this, check the documentation on configuration for the prefer keyword.
The typical reason is that system time and the time received from a reference disagree. This can be caused by the local clock that drifts very badly and needs a significant drift correction, or by a virtually bad time reference. I say virtually bad, because the client (i.e. your server) cannot decide whether random variations in network delay or variations in the time reference itself cause that observation. Not only because of that it is recommended to have several independent time references configured.
In any case you should keep an eye on the reachability register, on delay (see Q: 8.1.4. and Q: 8.1.2.) and on dispersion (jitter).
ntpd has problems controlling the system clock. Most likely the frequency of your timer interrupts is either too fast or too slow. Another possibility is a broken interface between ntpd and the operating system. In any case the problem is serious. If you suspect the first problem, you should adjust the value of tick to compensate the error (See Q: 8.2.5.1.).[2] If you are using the kernel discipline (see Q: 5.1.6.1.) and you are suspecting the second problem, try to use adjtime() instead.
Usually xntpd can compensate small and even not-so-small errors, but in this case the clock is too bad to be adjusted by the NTP algorithm. Any clock error of more than one minute per day is definitely too large to be corrected by NTP.
Example 8. Entries in logfile from xntpd
9 Jun 21:56:53 xntpd[116]: time reset (step) 0.706052 s 9 Jun 23:51:04 xntpd[116]: time reset (step) 0.821992 s 10 Jun 01:57:31 xntpd[116]: time reset (step) 0.720290 s 10 Jun 03:47:25 xntpd[116]: time reset (step) 0.855968 s
This means that in the period from 9 Jun 21:56:53 (excluding) to 10 Jun 03:47:25 (including), that is during 21032 seconds, xntpd added 2.398250 seconds (do not include the amount added during the first time step). Thus in each second 114.0286 microseconds should have been added.
You get a more accurate calculation when you do not run xntpd. Start the measurement by synchronizing your system to a NTP-server using e.g. ntpdate -b -s -p 4 -t 0.1 NTPserver. Complete the measurement with the same command after a few hours.
In your /var/log/messages (syslog file)file you will have 2 lines like
Jun 9 15:00:47 NTPclient ntpdate[334]: step time server 10.0.0.1 offset 0.009416 sec Jun 9 21:40:23 NTPclient ntpdate[515]: step time server 10.0.0.1 offset 2.718281 secUse this information to compute the number of microseconds to add to tick.
For some operating systems there is a tickadj utility that can be used to change the value of tick. See Section 3 and Q: 8.2.5.1. for a discussion on how to compute the necessary adjustment.
For ntp-4.1.0 (and most likely for all earlier releases as well), ntpdate can set the date to year 1933 when the current date is also completely wrong. According to an analysis by Michael Andres, the problem is caused by some overflow when adding two signed 32-bit numbers. The effect is visible if the difference between the current date and the system time is too big. Occasionally the user will see Can't adjust the time of day: Invalid argument.
As a patch has been suggested to fix the problem, recent version should no longer have that defect.
5. Messing with broken Hardware
Here is a procedure taken from an article by Andrew Hood:
Watch the value in ntp.drift and when it seems to stabilise continue at the next step.
Run tickadj without any options to get the value of tick.
Calculate a new value of tick as "newtick = oldtick*(1+drift/2^20)".
Run tickadj with the new value of tick.
Restart from the beginning.
Example 9. Correcting the value of tick
Here are the specific commands for Linux.
~# cat /etc/ntp.drift 269.799 ~# tickadj tick = 10000 ~# echo 'scale=7; t=10000*(1+269.799/2^20)+0.5; scale=0; t/1' | bc 10003 ~# tickadj 10003
The author points out that it can also be done with one single command:
~# echo "scale=7; `tickadj`; drift=`cat /etc/ntp.drift`; t=tick*(1+(drift)/2^20)+0.5; scale=0;t/1" | bc 10003
Example 10. Changing nsec_per_tick
For the Solaris operating system the variable nsec_per_tick is in nanoseconds and can be modified using adb (thanks to Thomas Tornblom):
The command echo 'nsec_per_tick/W 0t10000900' |adb -w -k makes the clock faster by 90 PPM, i.e. a drift value of 97 can be reduced to 7.
For FreeBSD there are two sysctls that you can use, machdep.i8254_freq and machdep.tsc_freq. Use the one that is being used on your machine to tell FreeBSD what the frequency of your clock is. (according to John Hay)
Changing the value of tick is considered an obsolete technology by Professor David L. Mills, and the tickadj utility will probably be missing in future releases of the NTP software. Even now the latest kernel clock model silently resets the values of tick to the default value when a PPS signal is detected.
With this new strategy clock errors of up to 500PPM can be corrected by the kernel clock machinery. Severely broken machines that really needed tickadj either should be running no NTP or an older version of the software.
6. Incompatibilities
New implementations of NTP determine the precision automatically, and do not allow setting it. This is a great benefit as you do not have to determine the value prior to setting it.
The statement above is valid for the system clock and should also be valid for the reference clock drivers.
7. Other...
Originally NTP has not been designed with dial-up connections in mind. Therefore it does not care very much about when to send out packets.
If you have defined an external server or peer, ntpd will periodically poll it. The polling interval is limited by the settings minpoll and maxpoll (See Q: 5.1.2.4. and Q: 5.1.5.1.). The virtual stability of the system clock determines whether the polling interval is reduced or increased.
However, increasing the polling interval may be a sub-optimal solution: ntpd will take longer for the initial synchronization, and it may become unable to catch up with the clock's drift.
For some operating systems you may be able to select what types of packets are allowed to open a dial-up connection.
The following solution has been donated by Eric W. Bates:
When using PPP on FreeBSD or NetBSD (Linux kernel does not properly support pppd's demand dialing; so you will have to solve this another way), I configured my pppd options to ignore traffic on the NTP port (snippet):
### demand dialing options
demand # only actually connect ppp on demand
holdoff 10 # after connection drops, wait 10
# seconds before dialing again
idle 1500 # drop connection after 25 minutes of
# no traffic
active-filter 'not port ntp' # don't regard ntp packets as link activityThen in the scripts ip-up and ip-down I start and stop xntpd (respectively):
# Start any IP activity here that should only run while the modem is # connected /usr/sbin/xntpd -p /var/run/xntpd.pid
# During boot, when pppd is first initialized a connection is always
# made (not clear why -- named?), but when xntpd is started at that
# time it does not write the PID file (not clear why -- filesystem not
# writable?); so there is a case where the PID file is not readable.
PIDFILE=/var/run/xntpd.pid
if [ -r $PIDFILE ]; then
kill -TERM $(cat $PIDFILE)
rm $PIDFILE
else
# Get the process ID (do the "grep -v" to exclude this search from
# the result.
kill -TERM $(ps ax | grep xntpd | grep -v grep | cut -c 1-5)
fiThis results in a ppp0 interface which is configured at boot and dials only when there is demand for IP on its route. Upon dial-up NTP is started and the sync traffic does not prevent the dial-up from timing out, allowing the modem to hang up. Upon hang-up, the NTP daemon is stopped.
This has worked nicely for me for some years. I recognize that frequent connect/disconnects tend to mess with ntpd's ability to sync, but my work habits are such that once the PPP is up and live, it tends to stay up for long periods. Good enough for a workstation at home.
8.2.1. Messages
- 1. Fatal Errors
- 2. Syntax Errors
- 3. Warnings
- 8.2.1.3.1. Previous time adjustment didn't complete
- 4. Spurious and unexpected Messages
1. Fatal Errors
This message typically indicates that a connection could not be made because the service is not available. See Q: 8.2.1.1..
No response was received within the timeout interval. Either the network did drop the request or the answer, or it delayed it considerably, or the server did not respond. One reason for the latter would be a configuration line like this:[3]
restrict default ignore
If you see that message in your log file, the system time was not set by ntpdate. There are several possible reasons:
ntpdate failed to communicate through UDP port 123. This could be caused by some packet filtering or by firewalls. Unfortunately, using option -d to turn on debugging also changes the port ntpdate uses.
If ntpdate works with option -d, you should try option -u to use an unpriviledged port. In any case you should check your packet filtering.
2. Syntax Errors
The keyword precision is no longer known by the configuration parser. Most likely you are using a configuration file intended for an older version of the NTP software. See also Q: 8.2.6.1..
3. Warnings
Using adjtime() your system clock can be corrected by some amount of time (See also Q: 5.1.6.1.). Normally xntpd will only use small amounts that can be applied within one second. However, if you disallow time steps, the last correction may be not completed yet, and xntpd is unable to apply another correction until the last one is finished. This is what the message says.
4. Spurious and unexpected Messages
This message was seen in Windows/NT 4.0 with ntpd 4.0. The exact cause is not clear, but it seems some non-NTP applications also use port 123. The strange IP address (192.0.0.192) is a strong indication for this.
John Hay contributed the output of nslookup 192.0.0.192, namely 192.0.0.0-is-used-for-printservices-discovery----illegally.iana.net, and Professor David L. Mills stated: "Port 123 was assigned well before 1985 as per documented, but was in use probably from 1982." This means the address is not registered officially, and it should not be used. Also it seems some software for printers or printing is using that address together with NTP's port number.
Despite of worrying some system administrator the message indicates no trouble. Specifically no printer is known to need a NTP server to operate, nor do printers and NTP servers harm each other.[4]
8.3. Specific Products
8.3.1. PC Hardware
- 1. The CMOS RTC
- 8.3.1.1.1. How accurate is the CMOS clock?
- 8.3.1.1.2. How can I set the CMOS clock?
- 2. Enhanced Features
- 8.3.1.2.1. How can SMM affect Interrupt Processing?
1. The CMOS RTC
The CMOS real time clock (RTC) is responsible for preserving the date and time while the PC is turned off.
Some people say the CMOS RTC is much more accurate than the timer interrupt in terms of frequency error. Actually I don't know, but I have one concrete example:
A PC used a stratum 1 server with PPS had had a hardware fault, and it had been powered off for about 18 days. When running the typical frequency error was 15 to 17 PPM and when the system was rebooted the RTC clock was off by 18 seconds. That would be an error of roughly 12 PPM.
Basically ntpd only sets the system time of the operating system. Therefore setting the CMOS clock is the responsibility of the operating system and its associated tools. To make things worse, typical PC operating systems and the BIOS set the RTC to local time, while UNIX-like operating systems set the RTC to UTC.
Example 11. Linux
In Linux the RTC is either not updated at all, or just the minutes and seconds. The related kernel code has been revised several times, with different behaviour. Setting the system time manually does not update the RTC. Only if the STA_UNSYNC bit is cleared, the kernel will periodically update the RTC from the system time. Typically this happens every 11 minutes.
With the optional PPSkit-0.9.0 kernel patch the RTC is updated just like in other PC operating systems. In addition the automatic periodic update can be disabled completely (see the documentation that comes with the product).
There is also a user-space program to set the RTC, but it requires special privileges. Typically the utility is named hwclock.
2. Enhanced Features
Let me quote an explanation written by Poul-Henning Kamp from the newsgroup:
I was gathering some data for Professor David L. Mills today and they looked lousy to put it mildly, every 300-400 seconds I had a 40-50 microsecond peak in my data. After some debugging I know know what it was: The SMM mode interrupts to the BIOS.
This machine is brand new, and I had never put a PPS signal on it before, it uses the PIIX4 chip from Intel and appearantly the SMM BIOS gets called at regular (but not very precise) intervals to monitor temperatures and fans and whats not.
Needless to say, this could not be disabled in the BIOS setup.
I found out I could disable the SMI output from the PIIX4 to the CPU by clearing bit zero in the GLBCTL register in the third function of the 82371AB chip. You need to find the IO base address from register 0x40 in the PCI header, and add the 0x28 to that address. For my motherboard that ended up being 0xe428, your milage will vary, and you should Do The Right Thing to find this location.
Needless to say, the SMM BIOS will not be able to check if your CPU is able to make toast on if you disable it this way, so you'd better know what you're doing.
8.3.2. FreeBSD
Depending on your options for kernel configuration, the required functions may not be included in your kernel. Unfortunately autoconf seems unable to detect it.
Check if these options are included in your kernel config file:
options P1003_1B options _KPOSIX_PRIORITY_SCHEDULING options _KPOSIX_VERSION=199309L
Make sure you have done config ; make depend ; make ; make install ; reboot.
8.3.3. Irix
- 8.3.3.1. Why won't my SGI O2 sync?
Marc Brett contributed: (...) "We're running an O2 with IRIX 6.5, and it had a horrendous clock drift." (...) "All was cured by turning off NTP: and timed, running timeslave -P /var/adm/timetrim -H timeserver for a couple of days against a server with a known good clock, and then examining /var/adm/timetrim for the recommended timetrim value. Then edit the file /var/sysgen/mtune/kernel with the new timetrim value, rebuild the kernel with autoconfig -v, reboot, and voila! A stable clock. Turn off timeslave & timed, turn on NTP, and all is sweetness and light."
8.3.4. Linux
1. Kernel Messages
The function set_rtc_mmss() updates minutes and seconds of the CMOS clock from system time. It does not update the hour or date to avoid problems with timezones.[5] The message shown was added to make users and implementers aware of the problem that not all time updates will succeed.
Imagine the system time is 17:56:23 while the CMOS clock is already at 18:03:45. Updating just minutes and seconds would set the hardware clock to 18:56:23, a wrong value. The solution for this problem is either to wait a few minutes, or to install a kernel patch that fixes the problem. Normally a wrong time in the hardware clock will not show up until after reboot, or maybe after APM slowed down your system.
This message only appears if you are using the new nanokernel clock model, usually by having applied a recent PPSkit. Thus the message is coming directly from the kernel, or more precisely from adjtimex(). That function is used to implement adjtime(), ntp_gettime(), and ntp_adjtime(). The constant ADJ_TICKADJ (0x2000) is an extension to ntp_adjtime() that allows to set the value of tickadj (similar extensions use constants named ADJ_OFFSET_SINGLESHOT or ADJ_ADJTIME, ADJ_TICK).
Unfortunately that value is also used for MOD_NANO in the latest kernel clock algorithm. Therefore it was decided to relocate conflicting bits, thereby causing incompatibilities with old software that uses these extensions. However the decision is not critical as only very few programs use these extensions. At this point, it's also clear that the kernel can't decide whether a new program is using a new function, or an old program is trying to use the old function (thus the vague wording).
If you really need the new functionality, you should recompile your application using the current timex.h header file. If it still fails, you'll have to recompile the C library, or write a replacement function that is linked instead of the routine from the C library.
2. Serial Port
Between releases 2.0 and 2.2 of the Linux kernel the serial driver has been optimized for throughput. The new driver does not generate an interrupt for each character received, but instead when either the UART's receive buffer exceeds a threshold of typically ten characters, or when the next timer interrupt is scheduled.
The new default introduces an inaccuracy for received characters up to 10ms. Fortunately you can tell the driver to deliver received characters as soon as possible using the flag ASYNC_LOW_LATENCY for the port. The command setserial /dev/refclock-0 low_latency in connection with a recent release of the setserial utility can do that.
Multiport serial cards are usually optimized for throughput, not for low latency. Therefore, some reference clock drivers may cause trouble.
In case you are already in trouble, and using a standard serial port is not an option, you can only try to find out what's wrong:
| cat /proc/tty/driver/serial will show some essential information about the serial ports. |
| Depending on the driver, ntpq's cl command may show some useful information (like the last received time code or error counters) |
| To see what ntpd is doing, you can use strace -p pid to attach to ntpd. |
Somewhere in the code cleanup between NTP v3 and NTP v4, the code to set the modem lines of the serial port got lost. The port has to be set up in a special way to provide power to the receiver.
For my receiver the command setserialbits /dev/refclock-0 -rts turns on power while ntpd is running. Some receivers care about polarity, some don't. You might try substituting -rts with -dtr.
For the RAWDCF PARSE driver there is a mode 14, that turns on power on the port, but my receiver (and others, too) had errors about every 10 seconds. I have reported the problem to the original author.
3. Networking
Here is a solution provided by Wolfgang Barth for SuSE Linux 6.3 using the ipchains packet filter (originally in German):
Set all default policies to DENY.
Allow the NTP protocol on interface ippp0:
$IPCHAINS -A ippp0_ou -p UDP -s $ippp0_ip 123 --dport 123 -j ACCEPT -l $IPCHAINS -A ippp0_in -p UDP -d $ippp0_ip 123 --sport 123 -j ACCEPT -l
Wolfgang writes (originally in German): "Chains ippp0_xx become active if interface ippp0 (my Internet connection) is used. Server to server connections use port 123 exclusively. I even set DNS to DENY, and it still works. You only have to remember not to use ntpq without -n because otherwise it will try to resolve the address."
Wolfgang Barth also suggests the following debugging procedure:
Rules are processed beginning at the top. It's useful to have all the rules (ipchains-save > file), because the logfile contains the rule numbers also. For example:
Mar 13 22:44:49 swobspace kernel: Packet log: ippp0_ou ACCEPT ippp0 PROTO=3D17 149.225.47.53:123 129.132.98.11:123 L=3D76 S=3D0x00 I=3D2201 F= =3D0x0000 T=3D64 (#12) Mar 13 22:44:49 swobspace kernel: Packet log: ippp0_in ACCEPT ippp0 PROTO=3D17 129.132.98.11:123 149.225.47.53:123 L=3D76 S=3D0x00 I=3D21191 = F=3D0x4000 T=3D239 (#16)
"In chain ippp0_ou rule #12 triggers the ACCEPT, and here's the corresponding line from the rule save file:"
-A ippp0_ou -s 149.225.25.39/255.255.255.255 123:123 -d 0.0.0.0/0.0.0.0 123:123 -p 17 -j ACCEPT -l
According to Hal Murray, at least RedHat Linux 7.1 was shipped with this line in /etc/ntp.conf:
restrict default ignore
Thus any NTP network messages are ignored. Either remove that offending line, or selectively allow individual addresses. Usually one would use the IP address, but see how the restrict directive really works. Consider this fragment:
restrict default ignore server 10.9.8.7 restrict 10.9.8.7
4. Hardware Clock
There are several possibilities besides using the BIOS:
You can read the clock using cat /proc/rtc (if CONFIG_RTC is set), or hwclock --show (hwclock is a newer replacement for the older clock program). C-programmers could use the ioctl() interface and RTC_RD_TIME (see /usr/include/linux/mc146818rtc.h and /usr/src/linux/Documentation/rtc.txt).
You can set the clock using either hwclock --set (possibly with --utc) or the ioctl() interface and RTC_SET_TIME.
The kernel will normally read the clock during boot (when it does not know the timezone yet) and when APM had been active. When the kernel PLL is used, the system time will be written to the clock periodically (see also Q: 8.3.1.1.2. and Q: 8.3.4.1.1.). Setting or adjusting the time by other means will not update the hardware clock.
However beginning with PPSkit-0.9 the hardware clock will be updated if the system time is set. You can even set up the correct timezone (see Q: 8.3.4.4.2. for details).
See also Q: 8.3.1.1.2.. According to the README file that comes along with PPSkit-0.9, there are some new features:
The hardware clock's date and time is set whenever it is updated. Previously only the minutes and seconds were updated. Naturally this requires different treatment depending on whether the hardware clock is expected to run in UTC or local time.
The hardware clock is updated whenever the system time is set (actually it happens 0.5s after the next second begins, but that's only because of the strange hardware).
The interval for automatic updates of the RTC can be modified. Automatic updates can be disabled completely.
These changes were designed to make everybody happy. Therefore some new sysctl() functions were introduced. These variables can be accessed through files in /proc/sys/kernel/time:
- rtc_runs_localtime
Decides whether RTC is set to UTC or local time. A value of 0 means UTC.
- rtc_update
Determines the interval after which the RTC is updated. If the value is 0, no automatic update happens.
- timezone
Determines the kernel timezone. This is a pair of values: The first value determines the minutes west of GMT, and the second value determines whether DST is in effect. These values are used when the kernel has to convert UTC to local time.
As up to these changes most people did not care much about the kernel's timezone, the time zone is not set correctly in many cases. There is a trick to copy the current timezone to the kernel.[6] I use the following code in /sbin/init.d/boot.local (SuSE Linux):
timezone=$(date +%z | sed -e 's/\([0-9][0-9]\)\([0-9][0-9]\)/(60*10#\1+10#\2)/') TIMESYSCTL=/proc/sys/kernel/time [ -w $TIMESYSCTL/timezone ] && echo $((-$timezone)) 0 >$TIMESYSCTL/timezone [ -w $TIMESYSCTL/rtc_runs_localtime ] && echo 1 >$TIMESYSCTL/rtc_runs_localtime
For Slackware Linux the proper place seems to be rc.local. (Contributed by Richard M. Hambly)
5. Miscellaneous
You are using /sbin/kerneld for automatic module loading. Several modules do not take good care of the time during initialization. If you can spare the memory, please load the modules at boot time.
The original contributor remarks: "This once occured to me. The sound system was demand loaded. A small application told the time every 15 minutes (saytime running in cron). The ntp logging showed me that something strange happened every 15 minutes. I found out it was the loading of the sound module every 15 minutes."
In addition removal of modules also seems to block interrupts.
(According to John Sager) The interrupt frequency for DEC Alpha is 1024Hz. According to Section 3.2 the value of tick is 977µs. Unfortunately 1024*977 is 1000448, giving an intrinsic frequency error of 448PPM, even for a perfect crystal.[7]
As not all versions of the Linux kernel and of NTP daemons can handle such a large frequency error, there may be a problem. Watch out whether your frequency seems to get stuck at some magical value (See Section 8.1). Trying the latest versions might help.
8.3.5. Macintosh
According to Brian Bergstrand "If/when you upgrade to a PPC machine, OS 8.5 and above have a built in NTP client that can be activated in the Date & Time control panel."
Another product seems to be Vremya.
8.3.6. Oncore Compatibles
It seems this product speaks a different protocol than the original hardware. To complicate matters, Gary Sanders found out that "If you got your eval kit from Synergy Systems, the PPS output on the eval board is inverted from the older Oncores(...)". To really confuse the users "(...) Synergy has a simple wiring change on the eval board to fix it. The boards that are currently shipping have this fix incorporated."
Mark Martinec contributed: "I just stumbled across the specs of the 12-channel GPS receiver Motorola Oncore M12. Its acquisition time (time to first fix) for cold start is less than 60 seconds typical. See http://www.motorola.com/ies/GPS/pdfs/m12.pdf"
According to the documentation driver 30 should work for the UT+ "as long as they support the Motorola Binary Protocol". Furthermore the documentation recommends: "When first starting to use the driver you should definitely review the information written to the clockstats file to verify that the driver is running correctly."
Unfortunately some essential documentation can only be found in the source file (ntpd/refclock_oncore.c). Some anonymous person wrote in news://comp.protocols.time.ntp:
(...) When the GPS is in (navigation mode), the driver simply discards the timestamp, resulting in the "clk_noreply". The clock did indeed reply, but the driver just threw it away with no messages to inform me about what it was doing.
(...) yes, the GPS is indeed in Naviation mode. The Oncore driver does change the mode, even though the code comment quoted above says "don't do anything to change it" (mode 0).
(...) So I start using mode 1 instead, which initializes the Oncore with a user supplied position and then switches into Position Hold mode. Now in this new mode I am still getting clk_noreply, but now these messages are alternated with clk_badtime.
(...) The binary code is getting decoded just fine, I can print out hours, minutes, seconds. (...) I discover that clocktime fails because it thinks that the time offset between the GPS and my computer's clock is more than half a day!
(...) I do ntpdate to fix the clock, then run NTP. Hey, it works! HalleleujahPraiseTheLord.
8.3.7. Solaris
- 8.3.7.1. Is there some specific Support for Solaris?
- 8.3.7.2. Why doesn't xntpd step the Clock in Solaris 8?
- 8.3.7.3. Why is my Ultra-2 Server rebooting when running SunOS 5.6 and xntpd?
- 8.3.7.4. Why doesn't xntpd synchronize in Solaris 2.7?
- 8.3.7.5. What does the message NTP user interface routines not configured in this kernel. mean?
- 8.3.7.6. What is dosyncdr?
- 8.3.7.7. I have read some conflicting advice on the use of tickadj -s to ensure that the OS is not trying to synchronize the kernel clock to the Clock/calendar chip on Solaris systems. On recent Solaris systems, e.g. 2.5, 2.6, 7, and 8, how does one ensure that xntpd has full control of clock synchronization?
- 8.3.7.8. What causes occasional 2s Time Steps?
- 8.3.7.9. Why is xntpd using that much CPU?
- 8.3.7.10. Why does my System think the year is 1934?
- 8.3.7.11. Why won't ntpdate finish while booting Solaris?
As pointed out in Q: 4.1.7., some versions of NTP software are supported by the vendors directly. Others are more or less supported by the Open Source Community (read: newsgroup news://comp.protocols.time.ntp).
For vendor support try to get the Sun BluePrints™ titled Using NTP to Control and Synchronize System Clocks.[8] NTP support is available beginning with Solaris 2.6 and ntp-3.4y. Beginning with Solaris 8 the supported version is ntp-3-5.93e, one of the last releases of NTP version 3.
There's a patch, 109667 that lets xntpd always slew the clock. Beginning with revision 04 of the patch there is an option to turn that feature off.
In an article Casper H. Dik wrote:
"The kernel adjtimex code is broken when it was changed to support a kernel settable hz value. You'll see a "divide by 0" trap. This happens when the "constant" value in the timex structure is > 6. Bug id is #4095849."
Dirk A. Niggemann contributed (slightly adapted):
The problem is apparently fixed in Solaris 7 and 8 above a certain patch level (according to SunSolve bug-tracking docs. (...)) Minimum kernel release is s998_20 for Solaris 7 and s28_26 for Solaris 8 (again according to docs on SunSolve). All of the kernel PLL problems except for that described by Bug ID 4095849 are reputedly fixed in 2.6 kernel patch 101581-13 (current patch is 101581-22 so grab that if you need to upgrade). The interesting question is whether there is any way to test if the divide-by-zero fault panic has been fixed in this patch as well(...)
I believe these all to be public patches so people shouldn't need to have SunSolve access to get them.
Mike Nolan contributed (slightly edited):
(...) I have the following: SunOS xxxxx 5.6 Generic_105181-17 sun4m sparc SUNW,SPARCclassic running as a stratum-1 server with a PPS input (only). (...) At that patch level (from a fairly recent Recommended (free) patch cluster), the FLL bug has supposedly been fixed, and it runs somewhat better with it running. Note that the configure script doesn't check for all patchlevels automatically, so I configure with --disable-kernel-fll-bug by hand, after checking that the patchlevel is at least 105181-17 for 2.6 or 106541-07 for 2.7. (...)
The xntpd supplied with Solaris 2.7 fails to adjust the clock frequency on a Ultra 5, but it succeeds on a SPARCstation 10. The output of ntpq may look like this:
status=06f4 leap_none, sync_ntp, 15 events, event_peer/strat_chg, system="UNIX/Solaris 2.x", leap=00, stratum=2, rootdelay=3.330, rootdispersion=33.020, peer=28188, refid=pctick1a.dvm.klinik.uni-regensburg.de, reftime=bc8484e2.9d718000 Thu, Mar 23 2000 12:56:18.615, poll=6, clock=bc84850a.6a29c000 Thu, Mar 23 2000 12:56:58.414, phase=11.594, freq=0.00, error=13.32
The following messages can be found in the syslog file:
xntpd version=3.4y (beta multicast); Fri Aug 23 19:54:40 PDT 1996 (2) tickadj = 625, tick = 10000, tvu_maxslew = 61875 NTP user interface routines not configured in this kernel.
As it seems, it's a software problem that is related to the hardware. There is actually a patch (108338, obsoleted by patch 109409 (currently at revision 4)) that provides a different binary of xntpd 3.4y, and that version seems to work (contributed by Arthur Darren Dunham). Revision 4 also contains a fix for a root vulnerability in xntpd.[9] See also Q: 4.1.7..
James Kirkpatrick contributed: "Be sure to have the latest kernel patch 106541-10 or newer (fixes for some NTP issues went in at versions 9 and 4 and 1), as well as 108338 as was suggested (latest is version 1)."
See Q: 8.3.7.4..
There's a kernel variable named dosyncdr that influences how the kernel keeps time. Generally it's neither necessary nor recommended to change the value from the default. Only in Solaris 2.5.1 (where NTP was not officially supported) it was necessary to set dosyncdr manually to 0.
8.3.7.7. I have read some conflicting advice on the use of tickadj -s to ensure that the OS is not trying to synchronize the kernel clock to the Clock/calendar chip on Solaris systems. On recent Solaris systems, e.g. 2.5, 2.6, 7, and 8, how does one ensure that xntpd has full control of clock synchronization?
Generally see Q: 8.3.7.6.. Michael Sinatra wrote in news://comp.protocols.time.ntp:
My understanding is, after Solaris 2.6 "not necessary at all" is the correct answer. In the past you need to put set dosynctodr=0 in /etc/system; now, you are NOT supposed to do that. Moreover, you are NOT supposed to use tickadj.
After some experiments, Thomas Schulz found out:
This behavior is normal for Solaris when NTP is not running. This wandering is due to Solaris correcting the system clock from the hardware clock (the TODR). The hardware clock is assumed to be the more accurate one (and it is). This correction is done whenever the two clocks are more than about 1.5 to 2 seconds apart. You will see this behavior on any Solaris system if you wait long enough. This correction is not done if NTP is running. Of course on a system with a very bad clock this behavior will be much more obvious than on one with a better clock (no Sparc has a good clock).
In Solaris 2.6 there could be a problem if xntpd is started before nscd. Reversing the start order should fix the problem.
There is a bug in xntpd 3.4y provided with Solaris 2.6. The problem is known as Bug Id 4237366.
There is a special version of ntpdate in Solaris 7 and 8 that has a -w switch. Using that switch causes ntpdate to wait until a suitable NTP-server has been found. If this was not the case, the syslog will say something like NTPDATE[549]: waiting 300 seconds before trying again..
The fix is to either kill the ntpdate process, or to modify /etc/init.d/xntpd as needed.[10]
8.3.8. Sun Hardware
Rainer Orth explains:
This is an unfortunate consequence of the fact that Sun decided to use the Siemens 82532 ESCC (see se(7D)) serial controller instead of the older Zilog 8530 SCC (see zs(7D)) used in sun4m and the first sun4u (like Ultra 1 and 2) systems. This chip has a 32 byte FIFO, which causes this large (and varying) delay. I have an RFE open with Sun (Bug Id 4357306) to provide for an alternative low-delay mode in the se driver, since it's possible to reduce the fifo size to 1 byte. Currently, the 32 byte setting is hard-coded in the se driver; I hope to experiment with other settings with a driver built from Solaris 8 sources when I get around to some planned work on NTP kernel/ppsapi support for Solaris 8.
8.3.9. Trimble Clocks
If the device uses very short pulses (like 1 microsecond), the hardware or software may have trouble processing the pulse correctly (See Q: 8.2.2.2. and Q: 6.2.4.6.1.). Recent clocks feature a programmable pulse width. Using 100 or 200 milliseconds as width will assist you finding the right edge, assuming that the first edge is the more accurate one.
8.3.10. TrueTime
Most likely you are using NTP version 4 on your client while the firmware in your TrueTime box only knows about NTP version 3. If you are using NTP version 4 on the client, all outgoing protocol packets will also request version 4. If the server does not know about that version, these packets will simply be ignored.
Use ping to make sure that the network configuration and connection is working.
Locate and examine your NTP configuration file for server and peer statements. If your TrueTime box only knows about version 3, add version 3 to these lines. This will make the client use version 3 protocol packets for the specified server.
You might consult the vendor of your TrueTime box about a firmware upgrade that can handle version 4 packets.
John K. Doyle, Jr. contributed: "Another good quickie debugging technique is to point just about any Cisco brand router running just about any release of Cisco IOS (9.21 or later) at a TrueTime unit. Cisco handles (or doesn't care) the differing NTP protocol version numbers and was always happy with the TrueTime unit. This is how I knew that the TrueTime unit was OK even though xntp for Windows/NT said that it was unreachable."
8.3.11. Windows/NT Family
- 1. General
- 2. Implementations
- 8.3.11.2.1. Are there any known Bugs in Windows/2000's SNTP Server?
- 8.3.11.2.2. What about Bugs in Windows/XP's SNTP Client?
- 8.3.11.2.3. I want to synchronize time from my server running Windows/NT. Is TimeServ the correct solution? Are there other applications?
- 8.3.11.2.4. Why doesn't TimeServ synchronize to my NTP Server?
- 8.3.11.2.5. Where is the Documentation for the Windows/NT Version?
1. General
It seems Microsoft® SQL server occupies the socket address used for NTP. These messages can be found in the event log:
| Error in RegQueryValueEx fetching IpAddress parameter: The operation completed successfully. |
| create_sockets: ioctl(SIOCGIFCONF) failed: Overlapped I/O operation is in progress. |
The solution is to start NTP first, even though Microsoft® SQL server will complain about not getting a port or socket.
Nicholas Jenkins contributed:
(...) The obvious key to this all; however, that doesn't appear in the Microsoft® documentation is that the W32time service is, IN FACT, *NOT* running by default! So, the simple solution to the whole problem is to just change the "startup type" of the w32time service in the "services" control panel to automatic", rather than manual. Then, either reboot, or just "start" the service, and the time will sync as nicely as you could possibly want!
2. Implementations
According to David Woolley there are some anomalies in the implementation of SNTP in Windows/2000:
I just discovered that the office Windows 2000 domain controller and IIS machine have been configured to synchronise to our *nix time server (net time /setsntp:). A quick look at their behavour raises some serious concerns:
the stratum is always 2, even when the upstream server was stratum 3, and even when it has never been synchronised. xntpd and ntpd to at least 4.0.99j will synchronise to them even though they are only SNTP (and indicating a false level of reliability). Never synchronised Windows 2000 servers respond with a zero reference time and reference ID and are ignored, even though the leap bits are valid and the stratum is 2. ntptrace reports a root dispersion and synchronisation distance of 1.0 in all cases, but everything else seems to report zero, which makes me wonder whether ntptrace has SNTP detection code that is missing from the real daemon.
The xntpd used was the original Windows port and the ntpd was a Linux port with a reduced max distance (although this is not relevant and the fact that the server sends a distance of zero would defeat this measure, anyway).
This is an ntptrace through two Windows 2000 machines (goonhilly and hercnode1) and a Linux machine (stock Red Hat, NTP 3(?), called mailgate). The firewall blocks the next hop.
D:\>ntptrace goonhilly goonhilly.XXXXX.co.uk: stratum 2, offset -0.133238, synch distance 1.00000 hercnode1.XXXXX.co.uk: stratum 2, offset -0.141267, synch distance 1.00000 mailgate.XXXXX.co.uk: stratum 3, offset -0.018762, synch distance 0.04329 ntp1.uk.psi.net: *Timeout*For comparison, this is from another Red Hat box, cvs.
D:\>ntptrace cvscvs.XXXXX.co.uk: stratum 4, offset -0.020810, synch distance 0.05432 mailgate.XXXXX.co.uk: stratum 3, offset -0.021750, synch distance 0.04344 ntp1.uk.psi.net: *Timeout*This is a verbose trace, and after a rationalisation of the time service tree (taken from the NTP 4 Linux):
bicycle:~/ntp# ntptrace -v goonhillyserver 192.168.xx.xx, port 123 stratum 2, precision -7, leap 00 refid mailgate.XXXXX.co.uk delay 0.02638, dispersion 0.00000 offset -0.001865 rootdelay 0.00000, rootdispersion 1.00000, synch dist 1.00000 reference time: be926721.7c2c2d85 Thu, Apr 26 2001 10:21:37.485 originate timestamp: be927134.9e76c8b4 Thu, Apr 26 2001 11:04:36.619 transmit timestamp: be927134.9b90214a Thu, Apr 26 2001 11:04:36.607 server 192.168.xx.xx, port 123 stratum 3, precision -17, leap 00 refid ntp1.uk.psi.net delay 0.00175, dispersion 0.00000 offset -0.002226 rootdelay 0.08713, rootdispersion 0.02473, synch dist 0.06830 reference time: be92708a.3d74f000 Thu, Apr 26 2001 11:01:46.240 originate timestamp: be927134.a362f000 Thu, Apr 26 2001 11:04:36.638 transmit timestamp: be927134.a3b80a9d Thu, Apr 26 2001 11:04:36.639 ntp1.uk.psi.net: *Timeout*The relatively low difference between the offsets suggests that Windows/2000 does do frequency correction.
I found [RFC 2030] a little confusing, especially when combined with earlier versions, but my impression is that it is trying to say that SNTP servers should send stratum 0, leap 11 unless they are directly connected to a radio clock. (...)
Possibly the problems described in Q: 8.3.11.2.1. still apply. At least the following problems are known:
Online help suggests that only SNTP servers may be used, but SNTP is a proper subset of NTP, so any NTP server should work.
The client sends a symmetric active package, indicating its willingness to synchronize the server. However, most servers are set up to require authentication for symmetric active modes, and thus will ignore the request. Despite of that, it violates [RFC 2030].
David J. Taylor contributed:
I have heard that Win2K/XP syncs correctly to many Internet NTP servers using the Microsoft® provided protocol. Indeed, if it did not, I think there would knowledge around that it was broken. NIST provide some configuration information at:
http://www.boulder.nist.gov/timefreq/service/pdf/win2000xp.pdf
There are considerations about the role of the PC within the Domain that may prevent it from synchronising to a time source outside the Domain. Anyone having problems with this may wish to check the registry settings listed at:
http://support.microsoft.com/default.aspx?scid=kb;EN-US;q223184
8.3.11.2.3. I want to synchronize time from my server running Windows/NT. Is TimeServ the correct solution? Are there other applications?
Doug Hogarth wrote:
TimeServ is not a server -- it is a client (I am the author). Perhaps you just want the actual NTP binaries compiled for Windows/NT, such as a link near the bottom of http://www.five-ten-sg.com/.
Things may never be 100% clear because TimeServ (including SNTP client feature) was written before ntpd was ported to Windows/NT (if it had been ported then I wouldn't have too much need for writing TimeServ). Also the current version of "Windows/NT" (Windows/2000) includes built-in time service which can be SNTP client (and server, if configured appropriately) - so MS basically suggested that I stop working on TimeServ around 1.5 years ago.
Specifically if the error NetRemoteTOD failed for each PrimarySource occurs Doug Hogarth says: "Most likely reason for that error message is that your .ini file is in the wrong directory (typically it belongs in c:\winnt, don't forget to "timeserv -update" and restart the time service after correcting it). I am the author of TimeServ, feel free to email me if you have further questions - http://www.niceties.com/TimeServ.html"
Actually there is no special documentation for Windows/NT (AFAIK). Despite of that, the popular binary distribution seems to come without the HTML documentation from the source distribution. To make things worse, the URL found in the README file is rather unspecific.
Unless there is additional documentation it's recommended to get and unpack the source archive. The files you want can be found in the html subdirectory.
8.4. Reporting Bugs
Originally I would not believe that such a section is necessary, but there are actually reports like: "I'm using your software, but it doesn't work."
- 8.4.1. When should I report a Problem?
- 8.4.2. What should I report?
- 8.4.3. Where should I report?
- 8.4.4. What should never be sent?
Before reporting a problem, make sure that it is not a known bug, or maybe even a feature. Also try to make sure that the mistake is not at your side.
Then you could try to find out whether the problem has been reported before, and maybe you might even find a solution or helpful advise for your problem. Today's Internet search engines should make it easy to find such public reports in news://comp.protocols.time.ntp.
If it turns out that there is a newer version of the software, try it! Most likely you will be asked to exactly do that. Maybe your problem has already been solved.
Simply report what you have (hardware, operating system (name, vendor, version, patch revision), NTP software release, anything unusual), what you did (compilation protocols, configuration files, etc), what you got (syslog messages, error messages, unusual output, monitoring data), and what you expected (be as precise as possible).
For the first contact try to include the most essential data. Personally I think it's better to leave out any lengthy data you don't understand, than to include it. Most likely someone will ask for such data. So possibly save most data for later reference, but don't include it all in the first contact.
If you are using a precompiled binary, and you can contact the vendor or maker of it, do so. This is specifically true if you have a support contract, warranty, etc.
When using the open-source software, it's best to make a public report in news://comp.protocols.time.ntp. Many people will see it, and chances are high that someone either has the same problem, or maybe a solution already. It's also a good place if you feel unsure about the nature of the problem (bug or feature).
Only if you are confident that you have found a new problem, you should send electronic mail to the address found in the HTML documentation of the distribution.
Finally: When posting to news://comp.protocols.time.ntp, don't use "NTP" as subject. Similarly don't use the subject "NTP bug" when sending to a mailing list named ntp-bugs. Use a crispy short description of the problem. Instead of "software problem" write "CPU emits blue smoke every 1024 seconds" (if that's your problem) ;-)
Please do not send SPAM, advertising, basic configuration questions, computer viruses, or otherwise rotten material to the mailing list. You may be completely ignored in the future when doing so.
Any article sent to news://comp.protocols.time.ntp should be related to NTP.