Introduction
Computer network time synchronization technology has improved from a significant fraction of the second twenty years ago to submilliseconds of today. This has been due largely to the deepened understanding of the stochastic properties of the network paths and quartz oscillators used in modern computers as reported in []. However, this technology has reached a plateau where continued improvement in accuracy, precision and stability is probably not feasible with the means now available.
The fundamental limit in performance has always been the intrinsic resolution and stability of the oscillator used to implement the system clock, as well as the interrupt latencies involved. Older machines used a tick interval of 10 ms or so and an interpolation counter with typical resolution in the order of a microsecond, which is appropriate for the Unix time value formed from two 32-bit words, one for the seconds and the other for the microseconds within the secon.
On the other hand, processor speeds have improved dramatically over the last two decades, with result it may be possible to improve the accuracy some orders of magnitude beyond the microseconds of old. In fact, most modern Unix kernels can provide the time in both microseconds and nanosecond resolutions.
It remains the challenge to improve the clock discipline algorithm to the order consistent with the nanosecond resolution provided in modern kernels. This report considers the issues involved, suggests a design approach and describes an implementation based on that approach. It concludes with a set of performance measurements that confirm the claim that in many modern systems the system clock can be disciplined to the order of 50 ns, which is consistent with the best dissemination means of national standard time (GPS).
It is important to point out at the outset that accuracies of the order considered here require the use of a precision pulse-per-second (PPS) signal which is generated by most radio and satellite time receivers. Depending on the hardware involved, the signal can be connected directly to a parallel port pin or via a level converter and pulse regenerator []. For accuracies much less than a microsecond, particular attention must be given to signal line termination and matching, issues which are beyond the scope of this report.
The results of this investigation include a software distribution consisting of generic Unix kernel modifications designed to improve the accuracy of the system clock to the order of nanoseconds. It improves the accuracy and stability of the original design described in [] and a later one dated 29 March 1999. The latest improvements amount to a reduction of about ten times in the residual time and frequency errors. A general discussion on the issues involved in these designs is given in the documenation accompanying the software distribution and later in this report.
This distribution includes a set of subroutines to be incorporated in the Unix kernels of various architectures, including Digital (Alpha and RISC), Hewlett Packard, Sun Microsystems (SPARC) and Intel (PC). Changes since the original design described in [] are discussed later in this report. The new design has been implemented in the current Digital Unix, Sun Microsystems SunOS, Linux and FreeBSD kernels. Information included in this report should be helpful when porting this code to other architectures.
The primary purpose of these modifications is to improve timekeeping accuracy to the order less than a millisecond and, ultimately, to a nanosecond. They do this by replacing the clock discipline algorithm in a synchronization daemon, such as the Network Time Protocol [], with equivalent functionality in the kernel. While clock corrections are executed once per second in the daemon, they are executed at every tick interrupt in the kernel. This avoids sawtooth errors that accumulate between daemon corrections. The greatest benefit is when the clock oscillator frequency error is large (above 100 PPM) and when the NTP subnet path to the primary reference source includes only servers with these modifications. However, in cases involving long Internet paths and congested networks with large delay jitter or when the interval between synchronization updates is large (greater than 1024 s), the benefits are reduced. The primary reason for the reduction is that the errors inherent in the time measurement process greatly exceed those inherent in the clock discipline algorithm, whether implemented in the daemon or the kernel.
The software can be compiled for 64-bit machines, in which some variables occupy the full 64-bit word, or for 32-bit machines, where these variables are implemented using a macro package for double precision arithmetic. The software can be compiled for kernels where the time variable is represented in seconds and nanoseconds and for kernels in which this variable is represented in seconds and microseconds. In either case, and when the requisite hardware counter is available, the resolution of the system clock is to the nanosecond. Even if the resolution of the system clock is only to the microsecond, the software provides extensive signal grooming and averaging to minimize the reading errors.
Figure 1. Kernel Clock Discipline
Figure 1 shows the general organization of the kernel clock discipline algorithm. Updates produced by the synchronization daemon (in this case NTP) are processed by the hardupdate() routine, while pulse-per-second PPS signal interrupts are processed by the hardpps() routine. The phase and frequency predictions computed by either or both routines are selected by the interface described later in this report. The actual corrections are redetermined once per second and linearly amortized over the second at each hardware tick interrupt. The increment at each interrupt is calculated using extended precision arithmetic to preserve nanosecond resolution and avoid overflows over the range of tick interrupt intervals from 20 ms to less than 1 ms.
Both the hardupdate() and hardpps() routines include improved algorithms to discipline the computer clock in nanoseconds in time and nanoseconds per second in frequency, regardless of whether the kernel time variable has a precision of 1 ms, as in older architectures or 1 ns, as in the newer. There are two C-langauge source files which implement the nanosecond time discipline, ktime.c and micro.c. The ktime.c file includes code fragments that implement the hardupdate() and hardpps() routines, as well as the ntp_gettime() and ntp_adjtime() system calls that implement the API. These routines can be compiled for both 64-bit and 32-bit architectures. Detailed information on how these routines work can are given later in this report.
The micro.c file implements a nanosecond clock using the tick interrupt augmented by a process cycle counter (PCC) found in most modern computer architectures, including Alpha, SPARC and Intel. In its present form, it can be compiled only for 64-bit architectures. The nano_time() routine measures the intrinsic processor clock rate, then interpolates the nanoseconds be scaling the PCC to one second in nanoseconds. The design supports symmetric multiple processor (SMP) systems with common or separate processor clocks of the same or different frequencies. The system clock can be read by any processor at any time without compromising monotonicity or jitter. When a PPS signal is connected, the PPS interrupt can be vectored to any processor. The tick interrupt must always be vectored to a single processor, but it does not matter which one. The routine also supports a microsecond clock for legacy purposes.
At each processing step, limit clamps are imposed to avoid overflow and prevent runaway phase or frequency excursions. In particular, the update provided by the synchronization daemon is clamped not to exceed +-500 ms and the calculated frequency offset clamped not to exceed +-500 PPM. The maximum phase offset exceeds that allowed by the NTP daemon, normally +-128 ms. Moreover, the NTP daemon includes an extensive suite of data grooming algorithms which filter, select, cluster and combine time values before presenting then to either the NTP or kernel clock discipline algorithms.
The extremely intricate nature of the kernel modifications requires a high level of rigor in the design and implementation. Following previous practice, the routines have been embedded in a special purpose, discrete event simulator. In this context it is possible not only to verify correct operation over the wide range of tolerances likely to be found in current and future computer architectures and operating systems, but to verify that resolution and accuracy specifications can be met with precision synchronization sources. The simulator can measure the response to time and frequency transients, monitor for unexpected interactions between the simulated clock oscillator, PCC and PPS signals, and verify correct monotonic behavior as the oscillator counters overflow and underflow due to small frequency variations. The simulator can also read data files produced during regular operation in a real kernel, in order to determine the behavior of the modifications under actual conditions.
The kernels of both SunOS 4.1.3 and Digital Unix 4.0 have been modified to incorporate these routines. Both the ktime.c and micro.c routines were used in the Digital Unix kernel for the Alpha, which has a PCC. Only the ktime.c routine was used in the SunOS kernel, since the SPARC IPC used for test does not have a PCC. Each of the two systems includes provisions for a PPS signal using a serial or parallel port control signal. Correct operation has been confirmed using utility programs described later in this report and in the NTP distribution. The results of performance tests are described as well.
It is important to note that the actual code used in the Alpha and SPARC kernels is very nearly identical to the code used in the simulator. The only differences in fact have to do with the particular calling and argument passing conventions of each system. This is important in order to preserve correctness assertions, accuracy claims and performance specifications.
Background and Analysis
In order to understand how the new kernel algorithms operate to improve the accuracy of the system clock, it is necessary to examine in detail the behavior of an undisciplined clock oscillator. The accuracy attainable with NTP, or any other protocol that provides periodic offset measurements, depends strongly on the stability of the oscillator and its adjustment mechanism. Typical oscillators utilize a quartz or surface acoustic wave (SAW) resonator without specific temperature, mechanical or drive stabilization. The temperature dependency of these oscillators is typically in the order of a part-per-million (PPM) in frequency per degree Celsius temperature change.
In order to reduce the residual time errors to the order of nanoseconds, it is necessary to use a precision source, such as a cesium oscillator or GPS timing receiver, and a PPS interface. For the results described in this presentation, a cesium oscillator was used as the precision source and the PPS interface used a pin of either a serial or parallel port interface. The experiment plan involved the collection of sample offsets measured at the interface with the clock discipline disabled and the system clock allowed to free-run. These data were then saved in a file and used by the kern simulator described on the page to generate the plots.
Allan Deviation
As shown in [1], it is possible to characterize the behavior of a typical quartz oscillator in terms of its Allan deviation as a function of averaging interval. A typical plot can be approximated by two intersecting straight lines in log-log scales. In general, white phase noise (jitter), which is represented by a straight line with slope -1 on the plot, dominates at the smaller intervals, while random-walk frequency noise (wander), which is represented by a straight line with slope +0.5, dominates at the larger intervals. The intersection of the two lines is called the Allan intercept, which serves to characterize the particular synchronization source and clock oscillator.
Figure 1. Allan Deviation for Nanosecond and Microsecond
Kernels
Figure 2. Allan Deviation for Normal and APC-Enabled
Kernel
Figure 1 shows the Allan deviation characteristics for four experiments distinguished with reference to the leftmost end of each trace. The uppermost trace (1) represents a typical computer oscillator and microsecond kernel, as described previously. The next lower trace (2) represents another computer oscillator and the nanosecond kernel, as described in this presentation. In both of these cases a cesium oscillator and PPS interface were used as the source and the computer oscillator allowed to free-run over periods ranging from 1.5 days to 10 days. The next lower trace (3) represents a synthetic model with phase noise limited only by the resolution of the microsecond kernel clock. The bottom trace (4) represents a synthetic model with phase noise limited only by the resolution of the nanosecond kernel clock.
Figure 1 clearly shows the Allan deviation for each case and how it is affected by the intrinsic jitter and wander. At the smaller averaging intervals with the cesium oscillator and PPS interface, the characteristic is dominated by sample jitter and interrupt latencies. Typical sample jitter contributions include noise pickup on the interface cable, incorrect cable impedance terminations and the reading resolution of the system clock itself. However, case (2) achieves lower jitter than case (1), primarily because the reading resolution of the nanosecond kernel is much lower than the microsecond kernel. While cases (1) and (2) involve real signals and kernels, the remaining cases involve synthetic data representing the best that can be done with either the microsecond kernel (3) or nanosecond kernel (4). For these cases the wander parameter was set to coincide with case (2). Obviously, there is room for improvement; however, further refinement is beyond the scope of this presentation.
At the larger averaging intervals, the characteristic is dominated by wander due to the individual oscillator design, crystal drive level, temperature variation and power supply regulation. Obviously, case (1) achieves lower wander than case (2) by a significant factor. This was due to the fact that, in case (1) the ambient room temperature was held to a narrow range less than one degree Celsius, while in case (2) the temperature varied over a much wider range on a hot Summer day in Denmark.
The main motivation for constructing the Allan deviation plot is to determine the Allan intercept for each combination of signal source and clock oscillator. The intercept represents the optimum averaging interval for the best clock accuracy and stability. If the averaging interval is less than the intercept, errors due to jitter dominate,
while if greater than the intercept, errors due to wander dominate. The curves shown in Table 1 show intercepts that vary from 2 s for case (4) to 2000 s for case (1). For the best performance, it is necessary to tune the averaging intervals to match the intercept. Notwithstanding these observations, it is probably better to err on the high side of the intercept, since the slope of the wander characteristic is half that of the jitter characteristic. For the remainder of this presentation and unless otherwise noted, a compromise averaging interval of 128 s will be assumed.
Table 1. Allan Intercept
A more careful examination of the particular nanosecond kernel used for case (2) reveals an interesting and important design issue. The particular Intel chipset used by this kernel has provisions for automatic power control (APC), which can be enabled by a BIOS parameter. The effect of the APC on the Allan deviation is shown in Figure 2. If the APC is enabled, the upper trace results; if disabled, the lower trace results. Obviously, the APC has a significant affect on timekeeping performance.
The result of the APC on system timekeeping is shown in Figures 3 and 4. Figure 3 shows the phase offset with APC disabled over a 1000 s interval, while Figure 4 shows the offset with APC enabled over the same interval. The problem is immediately apparent as the occurrence of 50->m s spikes at intervals of about 250 s. There is no immediate explanation why these spikes occur, whether they occur in other contexts or whether they occur with other chipsets. Apparently, some chipsets make better timekeepers than others.
Figure 3. Phase Offset of Normal Kernel
Figure 4. Phase Offset of APC-Enabled Kernel
Phase and Frequency Offset Characteristics
The figures below show the phase and frequency characteristic for the nanosecond kernel (case (2) Figures 5 and 6) and microsecond kernel (case (1) Figures 7 and 8). It is important to remember that the data on these plots are derived from the oscillator control signal Vc of the feedback loop. See the page for further information. For these figures the cesium oscillator and PPS interface were used as the source for the PPS discipline. The cause of the higher wander with case (2) is readily apparent in the frequency offset characteristic of Figure 6, which is considerably more wiggly than Figure 8. In fact, there are some nasty discontinuities in Figure 6 due to unknown causes. From experience, Figure 8 is more typical of workstations in temperature controlled office environments. Note also the grass in Figure 8, which is absent in Figure 6. While this does not seriously affect the phase offset, the cause is probably due the fact the microsecond kernel can resolve time values to only 1 ms.
Figure 9. Phase Offset for Synthetic Kernel
Figure 10. Frequency Offset for Synthetic
The Effects of Averaging Interval
Throughout this presentation until this point, it has been assumed that the optimum performance (lowest standard error) is achieved when the averaging interval is equal to the Allan intercept. Figures 11 and 12 show the standard error for the nanosecond kernel (case 2) and microsecond kernel (case 1) as the averaging interval is varied from 4 s to 32768 s.
Figure 11. Standard Error for Nanosecond
Kernel
Figure 12. Standard Error for Microsecond
Kernel
The lowest standard error is reached at 50 s in Figure 11 and 500 s in Figure 12. These values should be compared with the Allan intercept for each case, 50 s and 2000 s, respectively. While the Allan intercept is an accurate predictor of optimum averaging interval for the nanosecond kernel, it is less so for the microsecond kernel. On the other hand, the valley is quite broad and results in only minor increase in standard error over the range from 100 s to 5000 s. From these data a value of 128 s appears a good compromise choice.
It should be noted that the PPS discipline uses the averaging interval differently for phase averaging and frequency averaging. An exponential average is used for phase discipline, while a simple average is used for frequency discipline. The weight factor used for the exponential average is the reciprocal of the averaging interval. With this design the combined effect of the two discipline loops becomes marginally stable at the lowest averaging interval of 4 s and explains why the traces shown in the figures rise so fast at the lowest end. The interval of 4 s is used only at startup and after a drastic change in system clock frequency is sensed. The discipline increases the interval after that until reaching the maintaining the interval shown on the plot.
Principles of Operation
The nanokernel clock discipline algorithm includes two separate but interlocking feedback loops. The PLL/FLL algorithm operates with updates produced by a synchronization daemon such as NTP, while the PPS algorithm operates with an external PPS signal and modified serial or parallel port driver. Both algorithms include grooming provisions that significantly reduce the impact of disruptions due to clockhopping, outages and network delay jitter. In addition, the PPS algorithm can continue to discipline the system clock frequency even if the synchronization sources or daemon fail.
PLL/FLL Algorithm
Extensive experience with simulation and practice demonstrates that the clock discipline algorithm must behave differently depending on the update interval. At relatively small update intervals, white phase noise dominates the error budget and a phase-lock (PLL) algorithm performs best. However, at relatively large update intervals, random-walk frequency noise dominates and a frequency-lock (FLL) algorithm performs best. The optimum crossover point between the PLL and FLL modes, as determined by simulation and analysis, is the Allan intercept. Accordingly, the PLL/FLL algorithm operates in PLL mode at update intervals of 256 s and smaller and in FLL mode for intervals of 1024 s and larger. Between 256 s and 1024 s the mode is specified by the API. This behavior parallels the NTP daemon behavior, except that in the latter the weight given the FLL prediction is linearly interpolated from zero at 256 s to unity at 1024 s.
The PLL/FLL algorithm is similar to the NTP Version 4 clock discipline algorithm, which is specially tailored for typical Internet delay jitter and computer clock oscillator wander. However, the kernel algorithm provides better accuracy and stability than the NTP algorithm, as well as a wider operating range. Figure 1 shows the functional components of both algorithms. While the figure shows some components implemented in the kernel, the NTP algorithm includes equivalent components. Both algorithms operate as a hybrid of phase-lock and frequency-lock feedback loops. The phase difference Vd between the reference source qr and system clock qc is determined by the synchronization protocol, in this case NTP. The value is then groomed by the NTP clock filter and related algorithms to produce the phase update Vs argument to the hardupdate() routine in the kernel. This value is processed by the loop filter to produce the phase prediction x and frequency prediction y. These predictions are used by the clock adjust process, which runs at intervals of 1 s, to produce a correction term Vc. This value adjusts the system clock oscillator frequency so that the system clock displays the correct time.
It is important to point out that the various performance data displayed on these pages were derived from the system clock control signal Vc, since this is the best estimator of the time error. However, this estimator does not include the clock reading error, which depends on the resolution of the oscillator counter. While the reading error with a modern architecture including a processor cycle counter is a few nanoseconds, older architectures may have reading errors of 1000 ns or more. In addition, the Vc signal necessarily varies with time, so the value depends on when it is sampled.
Figure 2. PLL/FLL Prediction Functions
The x and y predictions are developed from the phase update Vs as shown in Figure 2. As in the NTP algorithm, the phase and frequency are disciplined separately in PLL and FLL modes. In both modes x is the value Vs, but the actual phase adjustment is calculated by the clock adjust process using an exponential average with an adjustable weight factor. The weight factor is calculated as the reciprocal of the time constant specified by the API. The value can range from 1 s to an upper limit determined by the Allan intercept [1], which is set arbitrarily at 1024 s. In PLL mode it is important for the best stability that the update interval does not significantly exceed the time constant for an extended period.
The frequency is disciplined quite differently in PLL and FLL modes. In PLL mode, y is computed using an integration process as required to discipline the frequency; however, the integration gain is reduced by the square of the time constant, so becomes essentially ineffective above the Allan intercept. In FLL mode, y is computed directly using an exponential average with weight 0.25. This value, which was determined from simulation with real and synthetic data, is a compromise between rapid frequency adaptation and adequate glitch suppression.
PPS Algorithm
PPS signals produced by an external source can be interfaced to the kernel using a serial or parallel port and modified port driver. The on-time signal transitions cause a driver interrupt, which captures a timestamp and related data. The driver calls the hardpps() routine, which implements the PPS algorithm. This algorithm is functionally separate from the PLL/FLL algorithm; however, the two algorithms have interlocking control functions designed to provide seamless switching between them in cases when either the NTP source becomes unreachable or the PPS signal fails or exceeds nominal tolerances.
Figure 3. PPS Prediction Functions
The PPS algorithm shown in Figure 3 is called at each PPS on-time signal transition. The arguments include a system clock timestamp and a virtual nanosecond counter sample. The virtual counter can be implemented using the PCC in modern architectures or the clock counter in older architectures. The intent of the design is to discipline the clock phase using the timestamp and to discipline the clock frequency using the virtual counter. This makes it possible, for example, to stabilize the system clock frequency using a precision PPS source, such as a cesium or rubidium oscillator, which has not been calibrated to UTC. In such cases an external time source, such as a radio or satellite clock or even another NTP server, can be used to discipline the phase. With frequency reliably disciplined, the residual time errors can be reduced by increasing the averaging time as well as the update interval. Also, should the external source fail, the system clock will continue to provide accurate time limited only by the accuracy of the precision source.
Values passed to the hardpps() routine are rigorously groomed to insure correct frequency, reject glitches and reduce incidental jitter. However, the design tolerates occasional dropouts and noise spikes. A frequency discriminator rejects timestamps more than +-500 PPM from the nominal frequency of 1 Hz. The virtual counter samples are processed by an ambiguity resolver that corrects for counter rollover and anomalies when a tick interrupt occurs in the vicinity of the second rollover or when the PPS interrupt occurs while processing a tick interrupt. The latter appears to be a feature of at least some Unix kernels, which rank the serial port interrupt priority above the timer interrupt priority.
The discriminator samples are processed by a 3-stage shift register operating as a median filter. The median value of these samples is the phase estimate and the maximum difference between them is the jitter estimate. The PPS phase correction is computed as the exponential average of the phase estimate with weight equal to the reciprocal of the frequency calibration interval described below. In addition, a jitter statistic is computed as the exponential average of the jitter estimate with weight 0.25 and reported as the jitter value in the API.
Typical PPS signal interfacing designs seldom include provisions to suppress large spikes when connecting cables pick up electrical transients due to light switches, air conditioners and water pumps, for example. These turn out to be the principle hazard to PPS synchronization performance. In the PPS algorithm a spike (popcorn) suppressor rejects phase outlyers with amplitude greater than 4 times the jitter statistic. This value, as well as the jitter averaging weight, was determined by simulation with real and synthetic PPS signals. Each occurrence of this condition sets a bit in the status word and increments the jitter counter in the API. Surviving phase samples discipline the system clock only if enabled by the API.
The PPS frequency is computed directly from the virtual counter difference between the beginning and end of the calibration interval, which varies from 4 s to a maximum specified by the API. When the system is first started, the clock oscillator frequency error can be quite large, in some cases 100 PPM or more. In order to avoid ambiguities throughout the performance envelope, the counter differences must not exceed the tick interrupt interval, which can be less than a millisecond for some systems. The choice of minimum calibration interval of 4 s insures that the frequency remain valid for frequency errors up to 250 PPM with a 1-ms tick interval.
The actual PPS frequency is calculated by dividing the virtual counter difference by the calibration interval length. In order to avoid divide instructions and intricate residuals management, the length is always a power of 2, so division reduces to a shift. However, due to signal dropouts or noise spikes, either the length may not be a power of 2 or the signal may appear outside the valid frequency range. Each occurrence of this condition sets a bit in the status word and increments the error counter in the API.
The required frequency adjustment is computed and clamped not to exceed +-100 PPM. This acts as a damper in case of abrupt changes that can occur at reboot, for example. Each occurrence of this condition sets a bit in the status word and increments the wander counter in the API. The PPS frequency is adjusted accordingly, but controls the system clock only if enabled by the API. In addition, a wander statistic is calculated as the exponential average of frequency adjustments with weight 0.25. The statistic is reported as the wander value in the API, but not otherwise used by the algorithm.
Operation Controls
It is important at this point to observe the PPS frequency determination is independent of any other means to discipline the system clock frequency and operates continuously, even if the system clock is being disciplined by the synchronization daemon or PLL/FLL algorithm. The intended control strategy is to initialize the PPS discipline state variables, including PPS frequency, median filter and related values during the interval the synchronization daemon is grooming the initial protocol values to set the clock.
When the NTP daemon recognizes from the API that the PPS frequency has settled down, it switches the clock frequency discipline to the PPS signal, but continues to discipline the clock phase using its own algorithm. When the mitigated phase offset is reduced well below +-0.5 s, to insure unambiguous seconds numbering, the daemon switches the clock phase discipline to the PPS signal. Should the synchronization source or daemon malfunction, the PPS signal continues to discipline the clock phase and frequency until the malfunction has been corrected.
The daemon continues to monitor the PPS phase offset and mitigated phase offset, in order to detect a possible PPS signal malfunction. If a significant discrepancy is discovered between the PPS phase offset and the mitigated phase offset, the daemon disables at least the PPS phase discipline and, if necessary, the PPS frequency discipline as well.
Proof of Performance
It is essential that the modified kernel be thoroughly tested before revenue service, since misbehavior of the system clock can be seriously disruptive in vital areas like archiving, electronic messaging and software building. Proof of performance requires tools found in the software distribution and also the Network Time Protocol distribution, which can be found at . Tools found in this distribution include jitter.c, which verifies correct system clock monotonicity, rollover and SMP operation. Tools found in the NTP distribution include the monitoring tools ntpq and ntpdc, the kernel test tool ntptime and the various statistics data files managed by the filgen facility.
The first thing is to verify the clock works correctly and has no antisocial behavior, such as forward or backward spikes, discontinuities, etc. The jitter.c test program in this distribution can be used for this purpose. It can be compiled with gcc or cc for the particular architecture involved. It should be run while the machine is not synchronized to a timing source. The most revealing test is to run two or more copies of the program in separate processes in a SMP system, if available.
The program repeatedly calls ntp_gettime() to read the system clock and writes the differences between successive readings to the standard output, which can of course be redirected to a data file. It sorts the first 20,000 differences and produces the beginning and ending tails of the resulting histogram to the standard error. A quick inspection of the histogram tails serves as a sanity check for correct operation. The beginning tail should contain only positive nonzero numbers, while the ending tail should not contain significant outlyers. The differences data file can be processed to produce a plot which typically shows subtle bumps at intervals corresponding to context-switches, cache flushes, tick interrupts, etc. For the ultimate test, a Fourier transform of these data should show a substantially flat envelope, demonstrating no significant cyclic phenomena which might create subtle beating effects in phase or frequency.
Once jitter testing is complete, the NTP daemon should be started and the machine synchronized to a timing source, such as a remote NTP server. For the best results, a PPS signal should be connected as described elsewhere. The ntptime program can be used to monitor the kernel operation. When the daemon first starts, it calls ntp_adjtime() to enable the kernel and specify the mode. Note the status word during as the synchronization process proceeds. It starts with a STA_UNSYNC (0x0040), which indicates unsynchronized. After the daemon starts, the status word should show STA_UNSYNC and STA_PLL (0x0041) for the older microsecond kernels and NTP-4 versions prior to 90c, or STA_NANO, STA_UNSYNC and STA_PLL (0x2041) when the kernel has been enabled for nanosecond operation.
If a PPS signal is connected, and before the clock is synchronized, the STA_PPSSIGNAL status bit should be lit. This indicates the PPS signal is present, but not necessarily working correctly. If the STA_PPSJITTER bit is lit, but none of the counters are incrementing, the signal is either excessively noisy or at the wrong frequency. After synchronization is achieved, the daemon should set the STA_PPSFREQ bit to enable frequency discipline and the STA_PPSTIME bit to enable time discipline. There may be intermediate conditions where one or more of the error bits are set, but these should settle out after a few minutes.
PPS Debugging
Following is a typical billboard produced by the ntptime program running on an Alpha. It shows the results first of a ntp_gettime() system call, which returns the current time and quality metrics, followed by a ntp_adjtime() system call, which returns the current system variables. In this case, the maximum error and estimated error are provided by the NTP daemon, which then are made available to user programs via the system calls. The remaining variables are produced by the kernel.
ntp_gettime() returns code 0 (OK)
time ba302a94.273a8000 Sun, Dec 27 1998 3:40:04.153, (.478303892),
maximum error 5095 us, estimated error 337 us.
ntp_adjtime() returns code 0 (OK)
modes 0x0 (),
offset 0.015 us, frequency 1.342 ppm, interval 256 s,
maximum error 5095 us, estimated error 337 us,
status 0x2107 (PLL,PPSFREQ,PPSTIME,PPSSIGNAL,NANO),
time constant 0, precision 0.001 us, tolerance 508 ppm,
pps frequency 1.342 ppm, stability 0.018 ppm, jitter 5.260 us,
intervals 74, jitter exceeded 145, stability exceeded 6, errors 0.
the last two lines of the ntptime billboard show the PPS signal quality and error residuals. The most useful error indications are the jitter and stability counters and their associated status bits. The STA_PPSJITTER bit is lit and the jitter exceeded counter incremented when a sudden time change over 500 >m s is detected. The STA_PPSWANDER bit is lit and the stability exceeded counter incremented when a sudden frequency change over 10 PPM is detected. The STA_PPSERROR bit is lit and the error counter incremented when the PPS discipline is reset. This can occur at reboot, when the daemon is restarted and after a considerable time when no PPS signal is present.
If the STA_PPSJITTER bit is lit, or the jitter exceeded counter increments continuously, or the jitter value is very large (over 100 >m s), the PPS signal has excessive jitter and is probably unsuitable as a synchronization source. This might occur if the PPS signal, when converted to RS-232 signal levels, passes over a considerable length of unterminated house wiring. If the STA_PPSWANDER status bit is lit, or the stability exceeded counter increments continuously, or the stability value is very large (over 1 PPM), the PPS signal is unstable and probably unsuitable as a synchronization source.
Proof of Performance
The final phase in the proof of performance exercise is to run the discipline for a day or so and collect the NTP filegen facility data for loopstats and peerstats files. Because of the way these data are recorded, the residual phase measurements shown in the loopstats file are misleading when the PPS signal is the synchronization source; however, the frequency measurements are accurate. Note that the frequency is updated at intervals shown in the ntptime billboard, ultimately 128 s. The frequency may wander throughout the day and night, generally following the ambient temperature, but ordinarily not more than +-0.1 PPM. Accurate phase measurements can be determined by running grep on the peerstats file and looking for the string "127.0.0.1". Normally, and even with a good PPS signal and when the kernel is not operating in nanosecond mode, the residual offsets should only rarely exceed +-1 >m s. The best behavior with a good PPS signal and nanosecond kernel mode has not yet been determined, but it should be better than this, perhaps in the tens of nanoseconds.
The following plots show typical performance in time and frequency for two architectures, Digital Alpha (churchy.udel.edu) and Sun IPC (grundoon.udel.edu) over a typical day. It is important to remember that the data on these plots is derived from the oscillator control signal Vc of the feedback loop. See the page for further information. A precision PPS signal is connected to each of these machines, but churchy is separated by several hundred feet of house wiring. While grundoon has a very solid connection, it is much slower than churchy and has only a microsecond clock.
Digital Alpha churchy.udel.edu
Sun IPC grundoon.udel.edu
In spite of these deficiencies, the plots show that both systems can keep good time well below the microsecond. For churchy the RMS time error is 53 ns, while for grundoon the RMS error is 51 ns. While the RMS errors for the two systems are about the same, it is evident from the plots that the actual error is lower on grundoon than churchy; however, there are significantly more spikes in the characteristic, probably due to various hardware and software latencies. While churchy shows peak errors less than 200 ns, with better signal conditioning, it should keep the time in the low tens of nanoseconds.
The folowing plot from the original distribution shows the resulting histogram (probability density function) in log-log coordinates for a DEC 3000 Alpha, which has a 7.5 ns cycle time. To generate this plot, jitter.c programs were run simultaneously in two user processes for several minutes and the output of one of them processed to generate the plot. There is plenty of memory for both processes, so that page faults should not occur after initialization. There is a significant secondary peak at about 28 >m s which is probably due to the timer interrupt routine latency. The peaks above that up to 500 >m s are probably due to various cache latencies, context switching and system management functions. The peak near 1 ms may be due to context switches as the result of timer interrupts, but this conjecture is unproven. The peak near 10 ms is probably due to timeslicing; it does not occur when only a single process is running. The distribution has a long tail up to a significant fraction of a second, but the number of samples is small and widely dispersed.
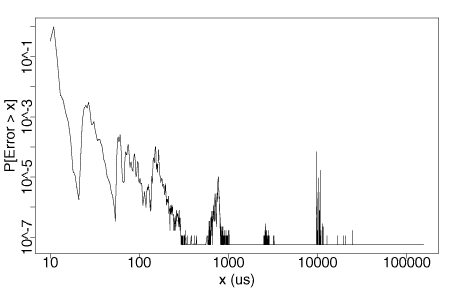 The following plot from the original distribution shows the integral (cumulative distribution function) of the same data in log-log coordinates. Over 80 percent of the samples are less than 20 >m s, while only one sample in a million is greater than the timeslice quantum (assumed 10 ms), and only one in 100 million is greater than 100 ms.
Kernel Application Program Interface
The application program interface (API) is used by the NTP protocol daemon (or equivalent) to discipline the system clock and set various parameters necessary for its correct operation. The API is used by application programs to read the system clock and determine its health and expected error values. Following is a description of the interface, as well as the control and monitoring variables involved.
The API consists of two Unix system calls, ntp_gettime() and ntp_adjtime(). The ntp_gettime() call returns the current system time in either timespec format in seconds and microseconds, or timeval format in seconds and nanoseconds, as determined by a status bit described below. In addition to the time value, this system call returns variables representing the maximum credible error and estimated error of the time value in microseconds. The ntp_adjtime() call is used to set and read certain kernel state variables according to a number of mode bits set in the call. To set the variables requires super user permission, but to read them requires no special permissions. Both system calls return a code indicating the current status of the system clock; that is, whether a leap second is pending or whether the clock is synchronized to a working reference source.
Following is a description of the various values used by the API, including state variables and control/status bits. Detailed calling sequences and structure definitions are in the timex.h header file included in the distribution.
Architecture Constants
The following parameters defined in the timex.h header file establish the performance envelope of the kernel clock discipline loop. Included are the current values for these parameters, although they may be changed in future. Note that changing these values may adversely affect overflow and rounding behavior and require re-engineering of the code segments.
MAXPHASE
MAXFREQ
Phase errors greater than MAXPHASE (0.5 s) or frequency errors greater than MAXFREQ (500 PPM) are beyond the range of the clock discipline algorithm. Values that exceed these limits are clamped to the limits before being used to discipline the system clock.
MINSEC
MAXSEC
For update intervals less than MINSEC (256 s), the clock discipline algorithm always operates in PLL mode; while, for update intervals more than MAXSEC (1024 s), the algorithm always operates in FLL mode. Between these two limits the mode is selected by the STA_FLL bit in the status word.
MAXTC
The range of time constants supported by the clock discipline algorithm is limited to the range 0 through MAXTC (10). The time constant is expressed as a power of two, so that zero corresponds to one second and 10 corresponds to 1024 s.
Status Word
The various functions of the clock discipline algorithm are controlled and monitored by the status word. The bits of this word are read and written using the ntp_adjtime() system call, but super user privilege is required to write them. The following read/write bits are defined by the API.
STA_PLL
Master enable switch for the PLL/FLL loop. The algorithm is responsive to time and/or frequency updates if set; otherwise, no change in the current time or frequency will be made other than to complete a pending phase adjustment. This bit does not affect the PPS loop.
STA_PPSFREQ
Enables the PPS frequency discipline independent of the STA_PLL bit.
STA_PPSTIME
Enables the PPS phase discipline independent of the STA_PLL bit.
STA_FLL
Selects the operating mode when the time constant is in the range 0 through 10. If set, operation is in FLL mode; otherwise, operation is in PLL mode.
STA_INS
STA_DEL
Controls the system clock behavior in the vicinity of a leap second insertion or deletion. See the Return Codes and the Leap-Second State Machine section on this page for how these bits are used.
STA_UNSYNC
Set by the synchronization daemon to indicate an unsynchronized or out-of-tolerance condition, but otherwise has no effect on the clock discipline algorithm.
STA_FREQHOLD
Set by the synchronization daemon to freeze the current frequency
while allowing the phase to be disciplined as usual. This bit is not
used by the NTP Version 4 daemon and is included only for legacy
purposes.
The following read-only status bits are defined by the API.
STA_PPSSIGNAL
Indicates the presence of a valid PPS signal. It is set by a valid PPS update and reset about two minutes during which no signal is present.
STA_PPSJITTER
Indicates a condition of excessive PPS phase jitter. See the Principles of Operation section for further details.
STA_PPSWANDER
Indicates a condition of excessive PPS frequency wander. See the Principles of Operation section for further details.
STA_PPSERROR
Indicates a calibration error in the PPS frequency measurement algorithm. See the Principles of Operation section for further details.
STA_CLOCKERR
Set by the external clock driver to indicate a fault in the hardware or driver.
STA_NANO
Set to indicate nanosecond mode or reset to indicate microsecond mode.
STA_MODE
Set to indicate FLL mode is in operation or reset to indicate PLL mode.
STA_CLK
Set to indicate the external clock is in use or reset to indicate the normal kernel clock variable is in use.
Return Codes and the Leap-Second State Machine
Occasionally, it is necessary to adjust the system clock in response to leap seconds as declared by national standards laboratories. The adjustments are in integral seconds that may be inserted or deleted in the local timescale, although no deletion has happened in the past and is extremely unlikely to happen in the future. The mechanism to recognize and disseminate the leap events themselves is beyond the scope of the API.
A leap event is implemented using a state machine in the kernel. Normally, the machine is in TIME_OK state and nothing special happens at midnight. In order to arm the machine for the event, the ntp_adjtime() system call sets the STA_INS or STA_DEL bit in the status word, which initializes the machine in either TIME_INS or TIME_DEL state to insert or delete the second, respectively. If in TIME_INS at second 86,400 of the current day, the machine repeats that second and transitions to TIME_OOP. One second later it transitions to TIME_WAIT. If in TIME_DEL at second 86,399 of the current day, it sets the system clock one second in the future and transitions to TIME_WAIT. The machine remains in this state until the STA_INS and STA_DEL bits are both reset in the status word, after which it transitions to TIME_OK.
It is extremely important to recognize the assumption in this design that the actual value of the system clock is read by a routine that always requires the system time to appear a monotonic process; that is, never runs backward. During the leap second itself, the system clock will appear to run one unit forward each time it is read, regardless of its prior value. Once the leap second has expired, the clock will resume normal operation. This is not a property of the API itself, but rather an intrinsic property of the system clock reading mechanism.
The current state of the machine is determined by the state word maintained by the kernel. When no error conditions are in effect, the value returned by the ntp_gettime() and ntp_adjtime() system calls is the current value of this word; otherwise, an error value is returned. Specific reasons for the error can be determined from the status word returned by the ntp_adjtime() system call. The following return codes are defined by the API.
TIME_OK
No leap second warning is in effect.
TIME_INS
A leap second will be inserted following second 86,400 of the current day.
TIME_DEL
A leap second will be deleted following second 86,399 of the current day.
TIME_OOP
A leap second insertion is in progress. Time might not be precisely coordinated between NTP server sites. This state occurs only during the actual leap second insertion and lasts for only one second.
TIME_WAIT
A leap second insertion has completed.
TIME_ERROR
The system clock is currently not synchronized to a reliable server. This state is declared when one or more of the following conditions are met.
STA_UNSYNC or STA_CLOCKERR is set.
Either the clock is not synchronized to a reliable server or a failure has occurred in the external clock or clock driver, if provisioned.
STA_PPSSIGNAL is reset and either STA_PPSFREQ or
STA_PPSTIME is set).
The synchronization daemon has requested use of the PPS signal, but
the signal has not been detected during the last two minutes.
STA_PPSTIME and STA_PPSJITTER are both set.
The synchronization daemon has requested PPS time discipline, but
the jitter has exceeded the limit.
STA_PPSFREQ is set and either STA_PPSWANDER or STA_PPSERROR is set.
The synchronization daemon has requested PPS frequency discipline, but either the frequency wander has exceeded the limit or a frequency
measurement has failed due to a glitch.
There are two additional return codes which can be produced by the kernel. These include the following system-dependent error numbers defined in the /usr/include/errno.h header file. Note that the values of these error numbers may collide with the above return codes in some systems.
EPERM
Not super user - attempt to change kernel variables without root privilege.
EINVAL
Invalid argument - attempt to set both MOD_MICRO and MOD_NANO or MOD_CLKB and MOD_CLKA simultaneously
Mode Control Bits
The following mode bits specify which kernel values are to be changed in the ntp_adjtime() system call, as well as the format used for time values and whether an external clock is selected.
MOD_OFFSET
MOD_FREQUENCY
MOD_MAXERROR
MOD_ESTERROR
MOD_STATUS
MOD_TIMECONST
MOD_PPSMAX
These bits control which field of the timex structure are used to update the corresponding kernel variable. The bits may be set in any combination. See the description below for which bits control which variable.
MOD_NANO
MOD_MICRO
These two bits control the scale used in the API interface (but not the actual operations used by the clock discipline algorithm). Only one of the two bits should be set. MOD_NANO selects seconds and nanoseconds (timespec format), while MOD_MICRO selects seconds and microseconds (timeval format). This applies to both the time value returned by ntp_gettime() and the offset used by ntp_adjtime(). Note that not all kernels can support nanosecond format. The recommended behavior is to select one or the other format and inspect the STA_NANO bit in the status word to determine the actual kernel mode. The default when the kernel is first booted is seconds and microseconds for legacy compatibility.
MOD_CLKA
MOD_CLKB
These two bits control the operation of an external clock, if present in the architecture. Only one of the two bits should be set. MOD_CLKB sets the STA_CLK bit in the status word, while the MOD_CLKA resets it. The behavior in response to the STA_CLK bit is beyond the scope of the current implementation.
The ntp_adjtime() System Call
The ntp_adjtime() system call is used to set and read kernel variables used by kernel. It operates using the timex structure described in the timex.h header file. This structure is used both to change the values of certain kernel variables and to return the current values. Root privilege is required to change the values. Following are the variables that can be read and written. The return codes are described in the Return Codes and the Leap-Second State Machine section on this page.
offset
If the MOD_OFFSET bit is set in the mode word, this variable updates the kernel time offset in nanoseconds, if the STA_NANO bit is set in the status word, or in microseconds if not.
freq
If the MOD_FREQUENCY bit is set in the mode word, this variable updates the kernel frequency offset in PPM. This is ordinarily done only when the clock discipline algorithm is first started, since the frequency is automatically determined by the algorithm after that. The format of this variable is in PPM with a 16-bit fraction field.
maxerror
If the MOD_MAXERROR bit is set in the mode word, this variable updates the kernel maximum error in microseconds. The error is automatically updated by the clock discipline algorithm after that and until the next update. The value is not used for any purpose other than to provide a conduit from the synchronization daemon to the user applications.
esterror
If the MOD_ESTERROR bit is set in the mode word, this variable updates the kernel estimated error in microseconds. The value is not used for any purpose other than to provide a conduit from the synchronization daemon to the user applications.
status
If the MOD_STATUS bit is set in the mode word, this variable updates the read/write bits in the status word.
shift
This variable is actually two variables, one write-only and the other read-only. When written, the value represents the maximum calibration cycle length expressed as a power of two, in seconds. When read, the value represents the current calibration cycle length expressed as a power of two, in seconds.
The following variables are read-only.
precision
Precision of the system clock, in nanoseconds if the STA_NANO bit is set in the status word, or in microseconds if not.
tolerance
Frequency tolerance of the clock discipline algorithm, in the same units as the freq variable described above. More precisely, the maximum clock oscillator frequency error that can be corrected by the clock discipline algorithm.
The following variables are read-only and present only if the PPS clock discipline code has been compiled and configured in the kernel. They are included in the timex structure definition to insure portability.
ppsfreq
Frequency calculated by the PPS loop, in the same units as the freq variable described above. This calculation is independent of all other means to adjust the system clock frequency. If enabled by the API and the PPS signal is within nominals, the clock frequency should be identical to this value.
jitter
Average phase jitter, in nanoseconds if the STA_NANO bit is set in the status word, or in microseconds if not.
stabil
Average wander, in the same units as the freq variable described above.
jitcnt
Count of excess phase jitter occurrences. See the Principles of Operation section for further details.
calcnt
Count of calibration intervals. See the Principles of Operation section for further details.
errcnt
Count of calibration error occurrences. See the Principles of Operation section for further details.
errcnt
Count of excess frequency wander occurrences. See the Principles of Operation section for further details.
The ntp_gettime() System Call
The ntp_gettime() system call is used to read the current system time and related error variables. It uses the ntptimeval structure described in the timex.h header file. This structure includes the following variables. The return codes are described in the Return Codes and the Leap-Second State Machine section on this page.
time
Current system clock time, in timespec format if STA_NANO is set in the status word; in timeval format if not.
maxerror
Maximum credible absolute error of the system clock, in microseconds. The value is initialized by the ntp_adjtime() system call and incremented by the kernel after that. The value is not used for any purpose other than to provide a conduit from the synchronization daemon to the user applications.
esterror
Estimated RMS error of the system clock, in microseconds. The value is initialized by the ntp_adjtime() system call, but not used for any purpose other than to provide a conduit from the synchronization daemon to the user applications.
Implementation Notes
Implementation of the nanokernel modifications involves two steps. The first is to verify the new kernel tick interrupt and PPS interrupt source code is compatible with the particular machine architecture, operating system and compiler. The kern simulator program is designed to do this using the actual kernel code fragments in both 32-and 64-bit architectures and with both microsecond and nanosecond kernel time variables. See the kern.h, timex.h and l_fp.h header files, the NANO and L64 defines, and accompanying commentary. See the description of the kern simulator program for directions on its use. Use the test.sh script to compile and test the simulator. This script uses the gcc compiler, but an ordinary cc compiler should work as well. Use the kern.dat script to simulate and test the code fragments throughout the complete operational envelope.
The second step is to extract the relevant code fragments from the ktime.c and micro.c source files and insert in the kernel source code. The ktime.c file in most cases can be used almost as-is, with linkages established from the BSD hardclock() routine or equivalent to service the tick interrupt and to the kernel routine to read the system clock and interpolate the nanoseconds or microseconds. The ntp_tick_adjust() routine replaces the code that increments the system clock by the tick interval, while the second_overflow() routine is called just after the test for seconds overflow. Typical modifications in this code are to the various copy-in and copy-out interfaces, set-priority calls and return codes.
Each architecture may have a different method to read the system clock as an atomic operation and to interpolate the nanoseconds or microseconds. The routines in the micro.c source file serve as typical examples, but these work only in 64-bit architectures. In the case of symmetric multiprocessor (SMP) systems, the implementation involves a special interprocessor interrupt about once per second for each processor, in order to calibrate the nanosecond interpolation and establish a base time and oscillator rate. The interrupt should be initiated from the tick interrupt routine after the routines in the ktime.c source file. From experience, this code is extremely delicate and requires very careful consideration for overflows, etc., that can happen in various places. The micro.c code was tested thoroughly in simulation, during which several oversights and undersights were found and corrected. See the commentary for specific considerations.
The PPS signal interfacing issues are beyond the scope of this discussion; however, the prudent course would be to modify the hardware driver to capture transitions of a modem control lead such as DCD and call the nano_time_rpcc() routine in micro.c, then pass the results on to hardpps() in ktime.c. Following is a code snip showing how this can be done:
struct timespec pps_time;
long nsec;
if (!edge)
return;
nsec = nano_time_rpcc(&pps_time);
hardpps(&pps_time, nsec);
One of the things to watch for in this code is the possibility that a modem control lead interrupt can in some architectures preempt a timer interrupt. The problem occurs when the modem interrupt and call to hardpps() occurs before the ntp_tick_adjust() routine is called from hardclock(). While the hardpps() routine has been coded with this possibility in mind, it helps to move the ntp_tick_adjust() call as early in the hardclock()
routine as possible.
Stay tuned for an IETF application program interface document on PPS API.
Changes Since RFC-1589
The nanokernel modifications require some changes in structure and behavior relative to RFC-1589 [1] and the report on which it is based [2]. However, the design provides backwards compatibility so that new and old NTP daemons can run in new and original kernels. Specific differences are described on this page.
Data Representation
Some variables, including the time, frequency and phase variables, are represented as 64-bit fixed point quantities, where the decimal point is between bit 31 and bit 32 (in either endian order). This format is used for time in nanoseconds and fraction and frequency in nanoseconds per second and fraction. In 64-bit machines, these variables are manipulated using native arithmetic and logical operations. In 32-bit machines, 64-bit operations are implemented using double precision arithmetic. The macro package defined in the l_fp.h header file hides the differences between the 32-bit and 64-bit versions.
The use of 64-bit arithmetic avoids two problems with the original kernel. One is the frequency calculation used when the tick interrupt frequency is not a power of two, which is the case for most architectures, including SPARC and Intel-based architectures. The calculation results in a frequency error of several percent, which is intolerable when frequencies must be computed with accuracies 1000 times better in the new kernel. The other problem is the leftover adjustment when the tick interrupt period does not evenly divide the number of microseconds or nanoseconds in one second, which is the case for the Digital Alpha and RISC architectures. In the original kernel the adjustment is performed once per second, in order to trim the frequency to the exact value. The jitter produced in this way is over 576 ms for the Alpha with 1024-Hz tick frequency. Obviously, this level of jitter is unacceptable in a nanosecond kernel. Both problems are solved using a 64-bit frequency variable, with which the frequency can be resolved to parts in 10^19 nanoseconds per second.
Changing Tick Interrupt Frequency
The original kernel requires a different timex.h header file for each different tick interrupt frequency, which means that the tick frequency cannot be changed once the kernel is built. The new kernel uses the same header file for all tick frequencies and the frequency can be changed dynamically during operation. Considering that nanosecond resolution is preserved at all tick frequencies, the only reason to change the frequency might be to improve resolution for scheduled events, which is limited to the tick interval.
Mode Switching
The original kernel can operate in either frequency-lock loop (FLL) or phase-lock loop (PLL) modes as selected by the ntp_adjtime() system call. The discipline time constant must be set by this system call to a value consistent with the poll interval used to update the clock. However, operation in FLL mode at poll intervals less than 256 s often results in instability, while operation in PLL mode at intervals greater than 1024 s results in poor frequency adaptation. The new kernel operates effectively in PLL mode if the update interval is less than 256 s and FLL mode if it is greater than 1024 s. Between these extremes, the STA_FLL bit in the status word can be used to select which mode to use. In any case, the particular mode in use can be determined by the STA_MODE status bit.
The original kernel has a limited range of time constants in PLL mode, the effect of which was to limit the poll interval to not less than 16 s. The new kernel extends this limit down to 1 s. Should a need for extremely rapid convergence arise, it is possible to use an initial poll interval of 1 s, in which case the time will converge in about a minute and the frequency in about an hour. Depending on the accuracy required, the poll interval can be increased to over one day, in order to reduce the network or operating system overhead. However, developers should note the new kernel requires a scale change in the time constant variable; in particular, the new time constant is 4 times larger than the old. Thus, a typical value of 2 in the original kernel corresponds to 6 in the new one. In addition, in the new kernel the time constant has meaning only in PLL mode. In FLL mode and PPS mode the time constant is fixed.
PPS Mode
Most of the changes between the old and new kernels are in the PPS code. In most practical cases, the full capability of the new kernel is realizable only if a precision PPS signal is available. The changes include the use of 64-bit variables for time and frequency and for several intermediate and temporary variables. In addition, there are fundamental changes in the way some algorithms work.
The original kernel is vulnerable to input signals that are not at the nominal 1-PPS frequency or are excessively noisy. In the new kernel a frequency discriminator is used to suppress samples that are outside a tolerance range of +-500 PPM. As in the original kernel, a three-stage median filter is used to suppress outlyer time samples and second order time differences are used to suppress outlyer frequency samples. In the new kernel the outlyer thresholds have been changed to 500 >m s for time (jitter) adjustments and between 500 PPM and about 2 PPM, depending on the calibration interval, for frequency adjustments.
While the new design allows for much larger tolerances and is much more resilient to noise and incorrect signal sources, there are specific limits due to the inherent ambiguity of the PPS signal itself when the pulse occurs approximately midway between two adjacent seconds. In order to prevent ambiguity errors, the sum of the maximum time offset and maximum frequency offset, expressed in microseconds over one second, must not exceed 500 >m s. In practice with NTP, these limits cannot even be approached, due to the conservative design of the protocol daemon.
The original kernel modifications average the PPS time over a 64-s interval and average the PPS frequency over intervals that start at 8 s and eventually grow to 256 s. As determined by experiment and simulation, these intervals are too large for typical room temperature quartz oscillators. The design of the new kernel reflects the choice of Allan intercept, which depends on the intrinsic phase noise of the PPS signal and the intrinsic stability of the oscillator. As determined by simulation and experiment, an appropriate value for the Allan intercept is 128 s. The time offset is averaged each second with weight factor equal to the reciprocal of this value, while the frequency offset is measured over an interval equal to the same value.
Previous versions of the kernel modifications have been vulnerable to relatively infrequent but relatively large time offset samples due to PPS signal spikes or occasional interrupt latency excursions. The new modifications use a median filter and popcorn spike suppressor to detect and remove outlyer samples. Running averages of jitter and wander are maintained as performance indicators. Values exceeding nominal limits are flagged and counted. These values along with error indicator bits and counters can be obtained via the kernel API and used as a quality indicator.
The frequency discipline is computed in the same way as the original kernel, except that great care is taken to avoid roundoff errors and wander excursions in the various calculations. When available, the discipline uses the PCC in each processor to interpolate between tick interrupts, resulting in an attainable accuracy of one nanosecond in time and one nanosecond per second in frequency. A running average of frequency differences is used in the same way as the running average of time offset samples. The value of the running average, interpreted as a frequency stability estimate, can be obtained via the kernel API and used as a quality indicator.
Legacy Issues
In order to preserve backward compatibility with previous kernel and NTP daemon versions, the default behavior is to operate in microsecond mode, where the scaling is based on microseconds and PPM. In this mode the offset, precision and PPS jitter are represented in microseconds. In addition, the PLL time constant is interpreted as in the original kernel. The kernel can be switched to nanosecond mode by setting the MOD_NANO mode bit. If the kernel is capable of nanosecond mode, it sets the STA_NANO status bit. In this mode the offset, precision and PPS jitter are represented in nanoseconds. If necessary, the kernel can be switched back to microsecond mode by setting the MOD_MICRO mode bit. The NTP daemon can determine whether the old or new kernel is present by attempting to switch to nanosecond mode and then testing the STA_NANO bit. Note that the original kernel and older NTP daemon versions do not implement these bits, so will continue to operate as before.
There is a new feature to set the PPS averaging interval via the API, which can be used to optimize performance according to the wander characteristics of the individual clock oscillator. The default averaging interval is 128 s, which is a good compromise for systems with uncompensated quartz crystal oscillators. In systems where the clock oscillator is stabilized by a temperature compensated or oven compensated crystal oscillator, rubidium gas cell or cesium oscillator, the averaging interval can be increased to optimize performance.
Utility Programs
Simulator Program
The kern.c simulator program linked with the ktime.c and micro.c subroutines in the distribution can be used to run a validation test suite in order to confirm that the kernel modifications work correctly in a particular architecture. The simulator can initialize state variables from the command line and write the feedback loop impulse response to the standard output. Alternately, the simulator can read input phase offset values from a data file and write the response to the standard output. See the source and header files for further details. Following is a list of command line flags interpreted by the program.
Option
Description
a
use alternate output format
c
specify PPS mode and averaging time (shift)
d
specify debug mode (trace on every tick/PPS
interrupt
f
specify initial frequency transient (PPM)
F
specify file name for data input
l
specify FLL mode and interval between polls (shift)
m
specify minimum simulation time (s) for trace
p
specify initial phase transient (ms)
r
specify random walk frequency parameter
s
specify maximum simulation time (s)
t
specify PLL mode and time constant (shift)
w
specify status word (not used here)
z
specify tick interrupt frequency (Hz)
In use, the kern.sh script should be run and the output compared with the model kern.out file in the distribution. Following is an example of the normal output format produced by the simulator.
start 0 s, stop 4000 s
state 0, status 2001, poll 64 s, phase 1000 us, freq 0 PPM
hz = 100 Hz, tick 10000000 ns
time offset freq _offset _freq _adj
0 1000.000 0.000 000f424000000000 0000000000000000 3b9aca0000000000
...
The program generates trace data lines in the format
time offset frequency hex_offset hex_frequency
hex_adjustment
The first three fields are the simulation time in seconds, phase error in microseconds and frequency error in PPM in decimal, and the last three fields are the corresponding time_offset, time_freq and time_adj state variables of the clock discipline loop in hexadecimal. In comparing the output of one architecture with another, minor differences may occur in the least significant digits. This is due to minor differences in input and output conversion routines, roundoff error, etc., and should not be considered significant.
An alternate output file format can be selected with the -a command line switch. This format consists of three fields corresponding to the first three fields of the standard format and in the same units. This format is intended for analysis and display programs like Matlab. In this format no header lines are produced. As an alternative to producing the impulse response of the feedback loop, an input data file can be specified using the -F command line option. The input file format consists of one update per line, where each line consists of two fields, the observation time in seconds and the phase offset in microseconds.
Histogram Program
The jitter.c program in the distribution can be used to generate a histogram of execution times for the ntp_gettime() system call, which involves a call on the nano_time() routine, an example of which is in kern.c. This is useful to determine the expected running time, as well as to look for anomalies, such as monotonic violations, etc. When operating properly, the histogram should show a sharp peak about 50 m s for a Sun IPC, 20 ms for a DEC 5000/240, 10 ms for a DEC 3000 Alpha, 8 ms for a HP 9000/735 and 2 ms for a Digital 433au. There should be no samples much below the peak; if samples of 1 >m s or less are found (the silly thing coredumps if less than zero), there is probably a bug in the implementation or the local clock has been set backward when the ntpd daemon is running while the program is running.
References
Mills, D.L. A kernel model for precision timekeeping, Network Working Group Report RFC-1589, University of Delaware, March 1994, 31 pp.
Mills, D.L. Adaptive hybrid clock discipline algorithm for the Network Time Protocol. IEEE/ACM Trans. Networking 6, 5 (October 1998), 505-514.
Mills, D.L. Unix kernel modifications for precision time synchronization. Electrical Engineering Report 94-10-1, University of Delaware, October 1994, 24 pp.
Mills, D.L. Network Time Protocol (Version 3) specification, implementation and analysis. Network Working Group Report RFC-1305, University of Delaware, March 1992, 113 pp.
The following plot from the original distribution shows the integral (cumulative distribution function) of the same data in log-log coordinates. Over 80 percent of the samples are less than 20 >m s, while only one sample in a million is greater than the timeslice quantum (assumed 10 ms), and only one in 100 million is greater than 100 ms.
Kernel Application Program Interface
The application program interface (API) is used by the NTP protocol daemon (or equivalent) to discipline the system clock and set various parameters necessary for its correct operation. The API is used by application programs to read the system clock and determine its health and expected error values. Following is a description of the interface, as well as the control and monitoring variables involved.
The API consists of two Unix system calls, ntp_gettime() and ntp_adjtime(). The ntp_gettime() call returns the current system time in either timespec format in seconds and microseconds, or timeval format in seconds and nanoseconds, as determined by a status bit described below. In addition to the time value, this system call returns variables representing the maximum credible error and estimated error of the time value in microseconds. The ntp_adjtime() call is used to set and read certain kernel state variables according to a number of mode bits set in the call. To set the variables requires super user permission, but to read them requires no special permissions. Both system calls return a code indicating the current status of the system clock; that is, whether a leap second is pending or whether the clock is synchronized to a working reference source.
Following is a description of the various values used by the API, including state variables and control/status bits. Detailed calling sequences and structure definitions are in the timex.h header file included in the distribution.
Architecture Constants
The following parameters defined in the timex.h header file establish the performance envelope of the kernel clock discipline loop. Included are the current values for these parameters, although they may be changed in future. Note that changing these values may adversely affect overflow and rounding behavior and require re-engineering of the code segments.
MAXPHASE
MAXFREQ
Phase errors greater than MAXPHASE (0.5 s) or frequency errors greater than MAXFREQ (500 PPM) are beyond the range of the clock discipline algorithm. Values that exceed these limits are clamped to the limits before being used to discipline the system clock.
MINSEC
MAXSEC
For update intervals less than MINSEC (256 s), the clock discipline algorithm always operates in PLL mode; while, for update intervals more than MAXSEC (1024 s), the algorithm always operates in FLL mode. Between these two limits the mode is selected by the STA_FLL bit in the status word.
MAXTC
The range of time constants supported by the clock discipline algorithm is limited to the range 0 through MAXTC (10). The time constant is expressed as a power of two, so that zero corresponds to one second and 10 corresponds to 1024 s.
Status Word
The various functions of the clock discipline algorithm are controlled and monitored by the status word. The bits of this word are read and written using the ntp_adjtime() system call, but super user privilege is required to write them. The following read/write bits are defined by the API.
STA_PLL
Master enable switch for the PLL/FLL loop. The algorithm is responsive to time and/or frequency updates if set; otherwise, no change in the current time or frequency will be made other than to complete a pending phase adjustment. This bit does not affect the PPS loop.
STA_PPSFREQ
Enables the PPS frequency discipline independent of the STA_PLL bit.
STA_PPSTIME
Enables the PPS phase discipline independent of the STA_PLL bit.
STA_FLL
Selects the operating mode when the time constant is in the range 0 through 10. If set, operation is in FLL mode; otherwise, operation is in PLL mode.
STA_INS
STA_DEL
Controls the system clock behavior in the vicinity of a leap second insertion or deletion. See the Return Codes and the Leap-Second State Machine section on this page for how these bits are used.
STA_UNSYNC
Set by the synchronization daemon to indicate an unsynchronized or out-of-tolerance condition, but otherwise has no effect on the clock discipline algorithm.
STA_FREQHOLD
Set by the synchronization daemon to freeze the current frequency
while allowing the phase to be disciplined as usual. This bit is not
used by the NTP Version 4 daemon and is included only for legacy
purposes.
The following read-only status bits are defined by the API.
STA_PPSSIGNAL
Indicates the presence of a valid PPS signal. It is set by a valid PPS update and reset about two minutes during which no signal is present.
STA_PPSJITTER
Indicates a condition of excessive PPS phase jitter. See the Principles of Operation section for further details.
STA_PPSWANDER
Indicates a condition of excessive PPS frequency wander. See the Principles of Operation section for further details.
STA_PPSERROR
Indicates a calibration error in the PPS frequency measurement algorithm. See the Principles of Operation section for further details.
STA_CLOCKERR
Set by the external clock driver to indicate a fault in the hardware or driver.
STA_NANO
Set to indicate nanosecond mode or reset to indicate microsecond mode.
STA_MODE
Set to indicate FLL mode is in operation or reset to indicate PLL mode.
STA_CLK
Set to indicate the external clock is in use or reset to indicate the normal kernel clock variable is in use.
Return Codes and the Leap-Second State Machine
Occasionally, it is necessary to adjust the system clock in response to leap seconds as declared by national standards laboratories. The adjustments are in integral seconds that may be inserted or deleted in the local timescale, although no deletion has happened in the past and is extremely unlikely to happen in the future. The mechanism to recognize and disseminate the leap events themselves is beyond the scope of the API.
A leap event is implemented using a state machine in the kernel. Normally, the machine is in TIME_OK state and nothing special happens at midnight. In order to arm the machine for the event, the ntp_adjtime() system call sets the STA_INS or STA_DEL bit in the status word, which initializes the machine in either TIME_INS or TIME_DEL state to insert or delete the second, respectively. If in TIME_INS at second 86,400 of the current day, the machine repeats that second and transitions to TIME_OOP. One second later it transitions to TIME_WAIT. If in TIME_DEL at second 86,399 of the current day, it sets the system clock one second in the future and transitions to TIME_WAIT. The machine remains in this state until the STA_INS and STA_DEL bits are both reset in the status word, after which it transitions to TIME_OK.
It is extremely important to recognize the assumption in this design that the actual value of the system clock is read by a routine that always requires the system time to appear a monotonic process; that is, never runs backward. During the leap second itself, the system clock will appear to run one unit forward each time it is read, regardless of its prior value. Once the leap second has expired, the clock will resume normal operation. This is not a property of the API itself, but rather an intrinsic property of the system clock reading mechanism.
The current state of the machine is determined by the state word maintained by the kernel. When no error conditions are in effect, the value returned by the ntp_gettime() and ntp_adjtime() system calls is the current value of this word; otherwise, an error value is returned. Specific reasons for the error can be determined from the status word returned by the ntp_adjtime() system call. The following return codes are defined by the API.
TIME_OK
No leap second warning is in effect.
TIME_INS
A leap second will be inserted following second 86,400 of the current day.
TIME_DEL
A leap second will be deleted following second 86,399 of the current day.
TIME_OOP
A leap second insertion is in progress. Time might not be precisely coordinated between NTP server sites. This state occurs only during the actual leap second insertion and lasts for only one second.
TIME_WAIT
A leap second insertion has completed.
TIME_ERROR
The system clock is currently not synchronized to a reliable server. This state is declared when one or more of the following conditions are met.
STA_UNSYNC or STA_CLOCKERR is set.
Either the clock is not synchronized to a reliable server or a failure has occurred in the external clock or clock driver, if provisioned.
STA_PPSSIGNAL is reset and either STA_PPSFREQ or
STA_PPSTIME is set).
The synchronization daemon has requested use of the PPS signal, but
the signal has not been detected during the last two minutes.
STA_PPSTIME and STA_PPSJITTER are both set.
The synchronization daemon has requested PPS time discipline, but
the jitter has exceeded the limit.
STA_PPSFREQ is set and either STA_PPSWANDER or STA_PPSERROR is set.
The synchronization daemon has requested PPS frequency discipline, but either the frequency wander has exceeded the limit or a frequency
measurement has failed due to a glitch.
There are two additional return codes which can be produced by the kernel. These include the following system-dependent error numbers defined in the /usr/include/errno.h header file. Note that the values of these error numbers may collide with the above return codes in some systems.
EPERM
Not super user - attempt to change kernel variables without root privilege.
EINVAL
Invalid argument - attempt to set both MOD_MICRO and MOD_NANO or MOD_CLKB and MOD_CLKA simultaneously
Mode Control Bits
The following mode bits specify which kernel values are to be changed in the ntp_adjtime() system call, as well as the format used for time values and whether an external clock is selected.
MOD_OFFSET
MOD_FREQUENCY
MOD_MAXERROR
MOD_ESTERROR
MOD_STATUS
MOD_TIMECONST
MOD_PPSMAX
These bits control which field of the timex structure are used to update the corresponding kernel variable. The bits may be set in any combination. See the description below for which bits control which variable.
MOD_NANO
MOD_MICRO
These two bits control the scale used in the API interface (but not the actual operations used by the clock discipline algorithm). Only one of the two bits should be set. MOD_NANO selects seconds and nanoseconds (timespec format), while MOD_MICRO selects seconds and microseconds (timeval format). This applies to both the time value returned by ntp_gettime() and the offset used by ntp_adjtime(). Note that not all kernels can support nanosecond format. The recommended behavior is to select one or the other format and inspect the STA_NANO bit in the status word to determine the actual kernel mode. The default when the kernel is first booted is seconds and microseconds for legacy compatibility.
MOD_CLKA
MOD_CLKB
These two bits control the operation of an external clock, if present in the architecture. Only one of the two bits should be set. MOD_CLKB sets the STA_CLK bit in the status word, while the MOD_CLKA resets it. The behavior in response to the STA_CLK bit is beyond the scope of the current implementation.
The ntp_adjtime() System Call
The ntp_adjtime() system call is used to set and read kernel variables used by kernel. It operates using the timex structure described in the timex.h header file. This structure is used both to change the values of certain kernel variables and to return the current values. Root privilege is required to change the values. Following are the variables that can be read and written. The return codes are described in the Return Codes and the Leap-Second State Machine section on this page.
offset
If the MOD_OFFSET bit is set in the mode word, this variable updates the kernel time offset in nanoseconds, if the STA_NANO bit is set in the status word, or in microseconds if not.
freq
If the MOD_FREQUENCY bit is set in the mode word, this variable updates the kernel frequency offset in PPM. This is ordinarily done only when the clock discipline algorithm is first started, since the frequency is automatically determined by the algorithm after that. The format of this variable is in PPM with a 16-bit fraction field.
maxerror
If the MOD_MAXERROR bit is set in the mode word, this variable updates the kernel maximum error in microseconds. The error is automatically updated by the clock discipline algorithm after that and until the next update. The value is not used for any purpose other than to provide a conduit from the synchronization daemon to the user applications.
esterror
If the MOD_ESTERROR bit is set in the mode word, this variable updates the kernel estimated error in microseconds. The value is not used for any purpose other than to provide a conduit from the synchronization daemon to the user applications.
status
If the MOD_STATUS bit is set in the mode word, this variable updates the read/write bits in the status word.
shift
This variable is actually two variables, one write-only and the other read-only. When written, the value represents the maximum calibration cycle length expressed as a power of two, in seconds. When read, the value represents the current calibration cycle length expressed as a power of two, in seconds.
The following variables are read-only.
precision
Precision of the system clock, in nanoseconds if the STA_NANO bit is set in the status word, or in microseconds if not.
tolerance
Frequency tolerance of the clock discipline algorithm, in the same units as the freq variable described above. More precisely, the maximum clock oscillator frequency error that can be corrected by the clock discipline algorithm.
The following variables are read-only and present only if the PPS clock discipline code has been compiled and configured in the kernel. They are included in the timex structure definition to insure portability.
ppsfreq
Frequency calculated by the PPS loop, in the same units as the freq variable described above. This calculation is independent of all other means to adjust the system clock frequency. If enabled by the API and the PPS signal is within nominals, the clock frequency should be identical to this value.
jitter
Average phase jitter, in nanoseconds if the STA_NANO bit is set in the status word, or in microseconds if not.
stabil
Average wander, in the same units as the freq variable described above.
jitcnt
Count of excess phase jitter occurrences. See the Principles of Operation section for further details.
calcnt
Count of calibration intervals. See the Principles of Operation section for further details.
errcnt
Count of calibration error occurrences. See the Principles of Operation section for further details.
errcnt
Count of excess frequency wander occurrences. See the Principles of Operation section for further details.
The ntp_gettime() System Call
The ntp_gettime() system call is used to read the current system time and related error variables. It uses the ntptimeval structure described in the timex.h header file. This structure includes the following variables. The return codes are described in the Return Codes and the Leap-Second State Machine section on this page.
time
Current system clock time, in timespec format if STA_NANO is set in the status word; in timeval format if not.
maxerror
Maximum credible absolute error of the system clock, in microseconds. The value is initialized by the ntp_adjtime() system call and incremented by the kernel after that. The value is not used for any purpose other than to provide a conduit from the synchronization daemon to the user applications.
esterror
Estimated RMS error of the system clock, in microseconds. The value is initialized by the ntp_adjtime() system call, but not used for any purpose other than to provide a conduit from the synchronization daemon to the user applications.
Implementation Notes
Implementation of the nanokernel modifications involves two steps. The first is to verify the new kernel tick interrupt and PPS interrupt source code is compatible with the particular machine architecture, operating system and compiler. The kern simulator program is designed to do this using the actual kernel code fragments in both 32-and 64-bit architectures and with both microsecond and nanosecond kernel time variables. See the kern.h, timex.h and l_fp.h header files, the NANO and L64 defines, and accompanying commentary. See the description of the kern simulator program for directions on its use. Use the test.sh script to compile and test the simulator. This script uses the gcc compiler, but an ordinary cc compiler should work as well. Use the kern.dat script to simulate and test the code fragments throughout the complete operational envelope.
The second step is to extract the relevant code fragments from the ktime.c and micro.c source files and insert in the kernel source code. The ktime.c file in most cases can be used almost as-is, with linkages established from the BSD hardclock() routine or equivalent to service the tick interrupt and to the kernel routine to read the system clock and interpolate the nanoseconds or microseconds. The ntp_tick_adjust() routine replaces the code that increments the system clock by the tick interval, while the second_overflow() routine is called just after the test for seconds overflow. Typical modifications in this code are to the various copy-in and copy-out interfaces, set-priority calls and return codes.
Each architecture may have a different method to read the system clock as an atomic operation and to interpolate the nanoseconds or microseconds. The routines in the micro.c source file serve as typical examples, but these work only in 64-bit architectures. In the case of symmetric multiprocessor (SMP) systems, the implementation involves a special interprocessor interrupt about once per second for each processor, in order to calibrate the nanosecond interpolation and establish a base time and oscillator rate. The interrupt should be initiated from the tick interrupt routine after the routines in the ktime.c source file. From experience, this code is extremely delicate and requires very careful consideration for overflows, etc., that can happen in various places. The micro.c code was tested thoroughly in simulation, during which several oversights and undersights were found and corrected. See the commentary for specific considerations.
The PPS signal interfacing issues are beyond the scope of this discussion; however, the prudent course would be to modify the hardware driver to capture transitions of a modem control lead such as DCD and call the nano_time_rpcc() routine in micro.c, then pass the results on to hardpps() in ktime.c. Following is a code snip showing how this can be done:
struct timespec pps_time;
long nsec;
if (!edge)
return;
nsec = nano_time_rpcc(&pps_time);
hardpps(&pps_time, nsec);
One of the things to watch for in this code is the possibility that a modem control lead interrupt can in some architectures preempt a timer interrupt. The problem occurs when the modem interrupt and call to hardpps() occurs before the ntp_tick_adjust() routine is called from hardclock(). While the hardpps() routine has been coded with this possibility in mind, it helps to move the ntp_tick_adjust() call as early in the hardclock()
routine as possible.
Stay tuned for an IETF application program interface document on PPS API.
Changes Since RFC-1589
The nanokernel modifications require some changes in structure and behavior relative to RFC-1589 [1] and the report on which it is based [2]. However, the design provides backwards compatibility so that new and old NTP daemons can run in new and original kernels. Specific differences are described on this page.
Data Representation
Some variables, including the time, frequency and phase variables, are represented as 64-bit fixed point quantities, where the decimal point is between bit 31 and bit 32 (in either endian order). This format is used for time in nanoseconds and fraction and frequency in nanoseconds per second and fraction. In 64-bit machines, these variables are manipulated using native arithmetic and logical operations. In 32-bit machines, 64-bit operations are implemented using double precision arithmetic. The macro package defined in the l_fp.h header file hides the differences between the 32-bit and 64-bit versions.
The use of 64-bit arithmetic avoids two problems with the original kernel. One is the frequency calculation used when the tick interrupt frequency is not a power of two, which is the case for most architectures, including SPARC and Intel-based architectures. The calculation results in a frequency error of several percent, which is intolerable when frequencies must be computed with accuracies 1000 times better in the new kernel. The other problem is the leftover adjustment when the tick interrupt period does not evenly divide the number of microseconds or nanoseconds in one second, which is the case for the Digital Alpha and RISC architectures. In the original kernel the adjustment is performed once per second, in order to trim the frequency to the exact value. The jitter produced in this way is over 576 ms for the Alpha with 1024-Hz tick frequency. Obviously, this level of jitter is unacceptable in a nanosecond kernel. Both problems are solved using a 64-bit frequency variable, with which the frequency can be resolved to parts in 10^19 nanoseconds per second.
Changing Tick Interrupt Frequency
The original kernel requires a different timex.h header file for each different tick interrupt frequency, which means that the tick frequency cannot be changed once the kernel is built. The new kernel uses the same header file for all tick frequencies and the frequency can be changed dynamically during operation. Considering that nanosecond resolution is preserved at all tick frequencies, the only reason to change the frequency might be to improve resolution for scheduled events, which is limited to the tick interval.
Mode Switching
The original kernel can operate in either frequency-lock loop (FLL) or phase-lock loop (PLL) modes as selected by the ntp_adjtime() system call. The discipline time constant must be set by this system call to a value consistent with the poll interval used to update the clock. However, operation in FLL mode at poll intervals less than 256 s often results in instability, while operation in PLL mode at intervals greater than 1024 s results in poor frequency adaptation. The new kernel operates effectively in PLL mode if the update interval is less than 256 s and FLL mode if it is greater than 1024 s. Between these extremes, the STA_FLL bit in the status word can be used to select which mode to use. In any case, the particular mode in use can be determined by the STA_MODE status bit.
The original kernel has a limited range of time constants in PLL mode, the effect of which was to limit the poll interval to not less than 16 s. The new kernel extends this limit down to 1 s. Should a need for extremely rapid convergence arise, it is possible to use an initial poll interval of 1 s, in which case the time will converge in about a minute and the frequency in about an hour. Depending on the accuracy required, the poll interval can be increased to over one day, in order to reduce the network or operating system overhead. However, developers should note the new kernel requires a scale change in the time constant variable; in particular, the new time constant is 4 times larger than the old. Thus, a typical value of 2 in the original kernel corresponds to 6 in the new one. In addition, in the new kernel the time constant has meaning only in PLL mode. In FLL mode and PPS mode the time constant is fixed.
PPS Mode
Most of the changes between the old and new kernels are in the PPS code. In most practical cases, the full capability of the new kernel is realizable only if a precision PPS signal is available. The changes include the use of 64-bit variables for time and frequency and for several intermediate and temporary variables. In addition, there are fundamental changes in the way some algorithms work.
The original kernel is vulnerable to input signals that are not at the nominal 1-PPS frequency or are excessively noisy. In the new kernel a frequency discriminator is used to suppress samples that are outside a tolerance range of +-500 PPM. As in the original kernel, a three-stage median filter is used to suppress outlyer time samples and second order time differences are used to suppress outlyer frequency samples. In the new kernel the outlyer thresholds have been changed to 500 >m s for time (jitter) adjustments and between 500 PPM and about 2 PPM, depending on the calibration interval, for frequency adjustments.
While the new design allows for much larger tolerances and is much more resilient to noise and incorrect signal sources, there are specific limits due to the inherent ambiguity of the PPS signal itself when the pulse occurs approximately midway between two adjacent seconds. In order to prevent ambiguity errors, the sum of the maximum time offset and maximum frequency offset, expressed in microseconds over one second, must not exceed 500 >m s. In practice with NTP, these limits cannot even be approached, due to the conservative design of the protocol daemon.
The original kernel modifications average the PPS time over a 64-s interval and average the PPS frequency over intervals that start at 8 s and eventually grow to 256 s. As determined by experiment and simulation, these intervals are too large for typical room temperature quartz oscillators. The design of the new kernel reflects the choice of Allan intercept, which depends on the intrinsic phase noise of the PPS signal and the intrinsic stability of the oscillator. As determined by simulation and experiment, an appropriate value for the Allan intercept is 128 s. The time offset is averaged each second with weight factor equal to the reciprocal of this value, while the frequency offset is measured over an interval equal to the same value.
Previous versions of the kernel modifications have been vulnerable to relatively infrequent but relatively large time offset samples due to PPS signal spikes or occasional interrupt latency excursions. The new modifications use a median filter and popcorn spike suppressor to detect and remove outlyer samples. Running averages of jitter and wander are maintained as performance indicators. Values exceeding nominal limits are flagged and counted. These values along with error indicator bits and counters can be obtained via the kernel API and used as a quality indicator.
The frequency discipline is computed in the same way as the original kernel, except that great care is taken to avoid roundoff errors and wander excursions in the various calculations. When available, the discipline uses the PCC in each processor to interpolate between tick interrupts, resulting in an attainable accuracy of one nanosecond in time and one nanosecond per second in frequency. A running average of frequency differences is used in the same way as the running average of time offset samples. The value of the running average, interpreted as a frequency stability estimate, can be obtained via the kernel API and used as a quality indicator.
Legacy Issues
In order to preserve backward compatibility with previous kernel and NTP daemon versions, the default behavior is to operate in microsecond mode, where the scaling is based on microseconds and PPM. In this mode the offset, precision and PPS jitter are represented in microseconds. In addition, the PLL time constant is interpreted as in the original kernel. The kernel can be switched to nanosecond mode by setting the MOD_NANO mode bit. If the kernel is capable of nanosecond mode, it sets the STA_NANO status bit. In this mode the offset, precision and PPS jitter are represented in nanoseconds. If necessary, the kernel can be switched back to microsecond mode by setting the MOD_MICRO mode bit. The NTP daemon can determine whether the old or new kernel is present by attempting to switch to nanosecond mode and then testing the STA_NANO bit. Note that the original kernel and older NTP daemon versions do not implement these bits, so will continue to operate as before.
There is a new feature to set the PPS averaging interval via the API, which can be used to optimize performance according to the wander characteristics of the individual clock oscillator. The default averaging interval is 128 s, which is a good compromise for systems with uncompensated quartz crystal oscillators. In systems where the clock oscillator is stabilized by a temperature compensated or oven compensated crystal oscillator, rubidium gas cell or cesium oscillator, the averaging interval can be increased to optimize performance.
Utility Programs
Simulator Program
The kern.c simulator program linked with the ktime.c and micro.c subroutines in the distribution can be used to run a validation test suite in order to confirm that the kernel modifications work correctly in a particular architecture. The simulator can initialize state variables from the command line and write the feedback loop impulse response to the standard output. Alternately, the simulator can read input phase offset values from a data file and write the response to the standard output. See the source and header files for further details. Following is a list of command line flags interpreted by the program.
Option
Description
a
use alternate output format
c
specify PPS mode and averaging time (shift)
d
specify debug mode (trace on every tick/PPS
interrupt
f
specify initial frequency transient (PPM)
F
specify file name for data input
l
specify FLL mode and interval between polls (shift)
m
specify minimum simulation time (s) for trace
p
specify initial phase transient (ms)
r
specify random walk frequency parameter
s
specify maximum simulation time (s)
t
specify PLL mode and time constant (shift)
w
specify status word (not used here)
z
specify tick interrupt frequency (Hz)
In use, the kern.sh script should be run and the output compared with the model kern.out file in the distribution. Following is an example of the normal output format produced by the simulator.
start 0 s, stop 4000 s
state 0, status 2001, poll 64 s, phase 1000 us, freq 0 PPM
hz = 100 Hz, tick 10000000 ns
time offset freq _offset _freq _adj
0 1000.000 0.000 000f424000000000 0000000000000000 3b9aca0000000000
...
The program generates trace data lines in the format
time offset frequency hex_offset hex_frequency
hex_adjustment
The first three fields are the simulation time in seconds, phase error in microseconds and frequency error in PPM in decimal, and the last three fields are the corresponding time_offset, time_freq and time_adj state variables of the clock discipline loop in hexadecimal. In comparing the output of one architecture with another, minor differences may occur in the least significant digits. This is due to minor differences in input and output conversion routines, roundoff error, etc., and should not be considered significant.
An alternate output file format can be selected with the -a command line switch. This format consists of three fields corresponding to the first three fields of the standard format and in the same units. This format is intended for analysis and display programs like Matlab. In this format no header lines are produced. As an alternative to producing the impulse response of the feedback loop, an input data file can be specified using the -F command line option. The input file format consists of one update per line, where each line consists of two fields, the observation time in seconds and the phase offset in microseconds.
Histogram Program
The jitter.c program in the distribution can be used to generate a histogram of execution times for the ntp_gettime() system call, which involves a call on the nano_time() routine, an example of which is in kern.c. This is useful to determine the expected running time, as well as to look for anomalies, such as monotonic violations, etc. When operating properly, the histogram should show a sharp peak about 50 m s for a Sun IPC, 20 ms for a DEC 5000/240, 10 ms for a DEC 3000 Alpha, 8 ms for a HP 9000/735 and 2 ms for a Digital 433au. There should be no samples much below the peak; if samples of 1 >m s or less are found (the silly thing coredumps if less than zero), there is probably a bug in the implementation or the local clock has been set backward when the ntpd daemon is running while the program is running.
References
Mills, D.L. A kernel model for precision timekeeping, Network Working Group Report RFC-1589, University of Delaware, March 1994, 31 pp.
Mills, D.L. Adaptive hybrid clock discipline algorithm for the Network Time Protocol. IEEE/ACM Trans. Networking 6, 5 (October 1998), 505-514.
Mills, D.L. Unix kernel modifications for precision time synchronization. Electrical Engineering Report 94-10-1, University of Delaware, October 1994, 24 pp.
Mills, D.L. Network Time Protocol (Version 3) specification, implementation and analysis. Network Working Group Report RFC-1305, University of Delaware, March 1992, 113 pp.