The measure quantifies the heterogeneity of the correlations and is defined as the distance between a correlation matrix and the nearest correlation matrix with constant off-diagonal entries. While a homogenous correlation matrix indicates every instance is the same or equally dissimilar, informative correlation matrices are not uniform, some subsets of instances are more similar and themselves are dissimilar to other subsets. A set of distinct clusters is highly informative (Figure 1).
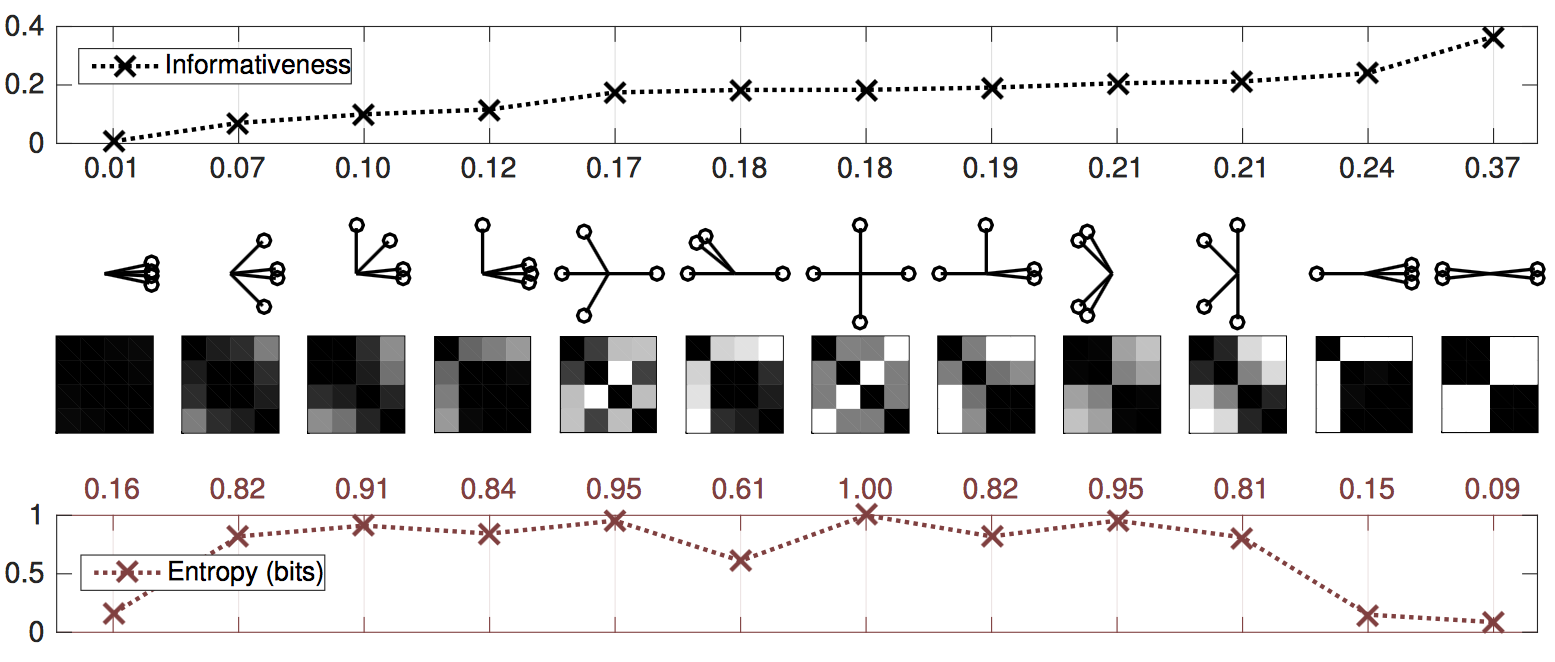
Figure 1: Informativeness versus von Neumann entropy for correlation matrices obtained from various configurations of four unit vectors. Both measures are minimal when the vectors are configured in a single cluster. Informativeness is higher for nontrivial clusterings, whereas entropy is maximized when the vectors are maximally separated.
Informativeness can be used as an function to choose between representations or perform parameter selection (Figure 2) or dimensionality reduction. Using it, we designed a convex optimization algorithm for de-noising correlation matrices that clarifies their cluster structure.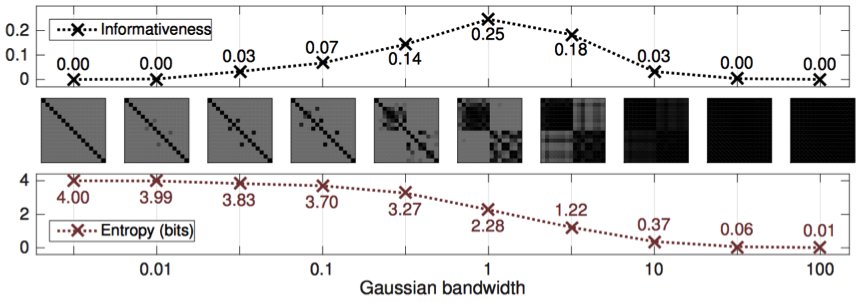
Figure 2: Informativeness versus the von Neumann entropy of correlation matrices obtained from a Gaussian kernel applied with varying bandwidths to a sample with 2 clusters.